Tworzenie kopii danych i baz danych na serwerze Storage
483 wyśw.
Wprowadzenie
Twoje dane są wrażliwe: ich utrata lub uszkodzenie mogłyby szybko doprowadzić do problemów w prowadzeniu Twojej działalności. Ponieważ zawsze istnieje ryzyko utraty danych, zalecamy wykonywanie kopii zapasowych co najmniej raz dziennie, najlepiej przy użyciu serwera czy rozwiązania do wykonywania kopii zapasowych innego niż Twoja infrastruktura produkcyjna.
OVHcloud oferuje gamę serwerów dedykowanych Storage dostosowanych do przechowywania kopii zapasowych i wyposażonych w minimum cztery dyski twarde. Istnieje możliwość wykorzystania tych zasobów do zapisywania kopii zapasowych infrastruktury hostowanej w OVHcloud lub u innego dostawcy za pośrednictwem sieci publicznej.
Niniejszy przewodnik wyjaśnia, jak skonfigurować odpowiadający Twoim potrzebom serwer kopii zapasowych, jak utworzyć drzewo kopii zapasowych oraz jak zautomatyzować wykonywanie kopii zapasowych danych z dwóch zdalnych serwerów za pośrednictwem protokołu SCP.
Wymagania początkowe
Powinieneś umieć:
- Administrować systemem Linux w zakresie podstawowym
- Łączyć się z serwerem za pomocą protokołu SSH
- Łączyć się z bazą danych
- Zapisywać kopie baz danych
- Instalować dystrybucje (w tym przypadku używamy dystrybucji Debian 9.4)
Powinieneś posiadać:
- Serwer Storage OVHcloud
- Infrastrukturę produkcyjną (VPS, serwery dedykowane, Public Cloud, itp.)
- Połączenie SSH skonfigurowane między serwerem kopii zapasowych a infrastrukturą produkcyjną
- Zalecane: sieć prywatna między serwerami (OVHcloud vRack)
W praktyce
Etap 1: wybierz odpowiedni tryb RAID
OVHcloud oferuje gamę serwerów dedykowanych, które posiadają kilka dysków twardych. W poniższym przykładzie prezentujemy RAID programowy (soft RAID) z czterema dyskami o pojemności 6 TB każdy.
OVHcloud umożliwia wybranie konfiguracji przechowywania danych, proponując RAID 0, 1, 5, 6 i 10. Każdy z tych rodzajów macierzy ma swoje zalety i wady w zakresie wydajności i elastyczności. W przypadku czterech dysków możesz przechowywać dane w konfiguracji RAID 5, 6 lub 10 (RAID 0 i 1 nie są w tym przypadku odpowiednie).
Poniżej kilka wyjaśnień dotyczących tych typów macierzy RAID.
RAID 5
Ten typ macierzy umożliwia rozłożenie Twoich danych pomiędzy co najmniej trzema dyskami twardymi. Na czwartym dysku przechowywane są dane o parzystości i jest on używany do odbudowy pozostałych dysków w przypadku uszkodzenia jednego z nich. Zyskujesz dzięki temu tolerancję na awarie dysku. Wydajność jest zwiększona w trybie odczytu, lecz nie w trybie zapisu (z powodu bitu parzystości).
W tym przypadku pojemność woluminu wynosi 18 TB.
RAID 6
Jest to udoskonalona wersja RAID 5 z minimum czterema dyskami twardymi. Dane o parzystości są zapisane na dwóch, a nie jednym dysku, co zapewnia większą redundancję (tolerancja na awarie dwóch dysków). Wydajność jest zwiększona w trybie odczytu i zapisu.
W tym przypadku pojemność woluminu wynosi 12 TB.
RAID 10
Rodzaj ten jest kombinacją dwóch procesów. Pierwszy polega na rozpraszaniu danych i przechowywaniu ich na dwóch dyskach, co przyczynia się do zwiększenia wydajności, ponieważ możesz korzystać z nich jednocześnie. Drugi proces polega na duplikacji danych w trybie odbicia lustrzanego na dwóch dyskach. Uzyskujesz wówczas tolerancję na awarie dwóch dysków w tym samym klastrze.
W tym przypadku pojemność woluminu wynosi 12 TB.
Nie można powiedzieć, że jeden RAID jest lepszy od innego, każdy z nich odpowiada na inne potrzeby. W przedstawionym przykładzie chcemy uzyskać maksymalną tolerancję na awarie dysków oraz zachować wysoką wydajność w trybie odczytu i zapisu. Rozpoczynamy zatem instalację RAID 6.
Etap 2: instalacja i konfiguracja serwera
Przejdź do Panelu klienta i wykonaj instalację systemu. Jak zostało wspomniane na początku, będziemy używać dystrybucji Debian 9.4. Więcej informacji znajdziesz w przewodniku Pierwsze kroki z serwerem dedykowanym.
Po wybraniu systemu do instalacji zaznacz pole Spersonalizuj konfigurację partycji.
Na tym etapie zmodyfikujesz typ macierzy RAID w Twoim katalogu /home (1) i, jeśli chcesz, rozszerzysz partycję (2).
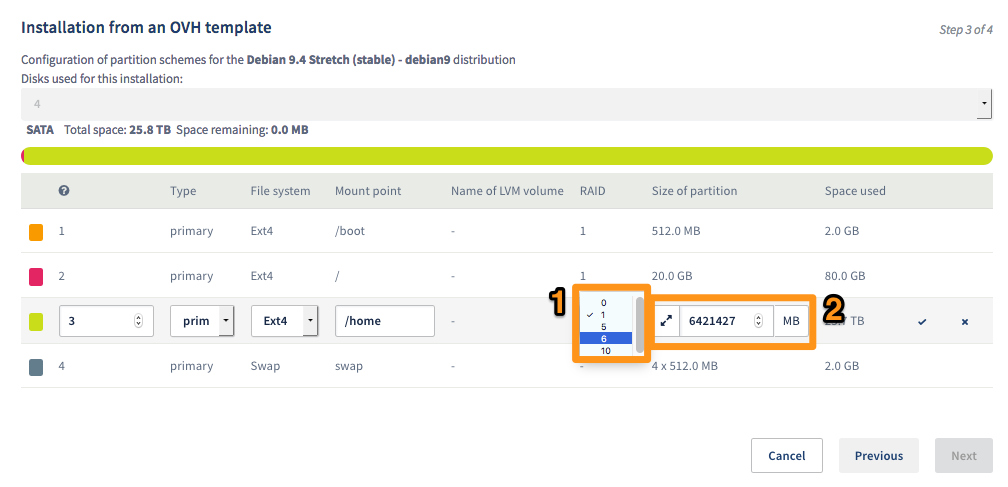
Rodzaj RAID dla katalogu /boot nie podlega modyfikacji.
Etap 3: tworzenie katalogów docelowych
Aby zachować porządek w przechowywaniu kopii zapasowych, utworzymy katalogi docelowe. Połącz się z Twoim serwerem dedykowanym za pomocą protokołu SSH, następnie wylistuj partycje:
Utwórz drzewo plików za pomocą komendy mkdir. W przedstawionym przykładzie na serwerze zapisywane będą kopie zapasowe dwóch produkcyjnych serwerów webowych. Tworzymy zatem dwa katalogi: serwer1 i serwer2. Każdy z nich będzie zawierał podkatalog dump do przechowywania kopii zapasowych SQL oraz podkatalog data przeznaczony do przechowywania danych WWW.
Używając komendy tree, możesz wyświetlić drzewo katalogu. Rezultat może wyglądać na przykład tak:
Etap 4: przesłanie danych z Twoich serwerów do serwera kopii zapasowych
Serwer kopii zapasowych jest teraz gotowy do zapisu kopii.
Jeśli Twoja infrastruktura produkcyjna hostowana jest w OVHcloud i posiadasz wykupioną usługę wirtualnej szafy vRack, przeprowadź odpowiednią konfigurację. Dzięki temu Twoje kopie zapasowe nie będą przesyłane przez sieć publiczną (Internet).
Etap ten wymaga połączenia z serwerami produkcyjnymi przez SSH, które z kolei same połączą się z serwerem kopii zapasowych przez protokół SCP. Aby tak się stało, wszystkie zasoby muszą mieć możliwość łączenia się przez SSH.
Wykonajmy najpierw kopię zapasową bazy danych MySQL, popularnie nazywaną dump. Informacje o zaawansowanych zastosowaniach znajdziesz w oficjalnej dokumentacji dotyczącej bazy danych.
Po skonfigurowaniu Twojej usługi SSH możesz połączyć się z serwerami produkcyjnymi i użyć komendy scp.
Jeśli zmodyfikowałeś port SSH Twojego serwera kopii zapasowych, dodaj argument -P.
Tę samą operację zastosuj do Twoich plików. Komenda scp pozwala również zapisywać kopie kompletnych katalogów.
Dostępne są także skuteczne (bezpłatne) narzędzia, takie jak rsync. Posiadają one zaawansowane funkcje, np. wznowienie wysyłki, która się nie powiodła.
Etap 5: tworzenie dziennego harmonogramu zadań za pośrednictwem cron
Łączenie się codziennie z każdym z serwerów kopii zapasowych może być uciążliwe. Istnieją podstawowe metody automatyzacji zadań. Najbardziej znaną z nich jest program Unix cron. Pozwala on zaplanować wykonanie kodu z dokładnością co do godziny, dnia, miesiąca albo roku. Każdy użytkownik programu Unix dysponuje swoją własną listą zaplanowanych zadań, zwaną crontab.
Ze względów bezpieczeństwa zalecane jest utworzenie dodatkowego konta użytkownika Unix i przypisanie do niego zaplanowanych zadań.
Aby edytować tę listę, uruchom:
Dodaj następującą linię, aby zaprogramować automatyczną wysyłkę Twojego pliku dump SQL na każdy dzień roku, godz. 02:00 rano.
Składnia crontab jest specyficzna; nie opisujemy jej dokładnie w niniejszym przewodniku, istnieją jednak strony WWW, gdzie można ją wygenerować.
Podsumowanie
Właśnie skonfigurowałeś własny serwer kopii zapasowych i zautomatyzowałeś w sposób podstawowy wykonywanie kopii zapasowych plików. Jest to ważny krok, dzięki któremu unikniesz utraty danych i zapewnisz bezpieczeństwo prowadzonej przez Ciebie działalności.
Jak wspomniano wyżej, istnieją również inne darmowe lub płatne sposoby optymalizacji wykonywania kopii zapasowych. Jeśli Twoje dane są wrażliwe, zalecamy ich zaszyfrowanie i przesyłanie wyłączenie w sieci prywatnej, takiej jak vRack OVHcloud.
-
Secure Shell (SSH) : un protocole de réseau sécurisé utilisé pour établir des connexions entre un client et un serveur. Il permet d'exécuter des commandes à distance de manière sécurisée. ↩

