Cluster SAP HANA avec SLES sur VMware on OVHcloud
164 vues
Objectif
Ce guide fournit les instructions pour configurer un cluster SAP HANA avec SLES sur VMware on OVHcloud en utilisant les services corosync et pacemaker.
Cette configuration réduit la durée maximale d'interruption admissible (RTO), en cas de coupure de service de la machine virtuelle ou de l'hôte ESXi sur la même localisation OVHcloud.
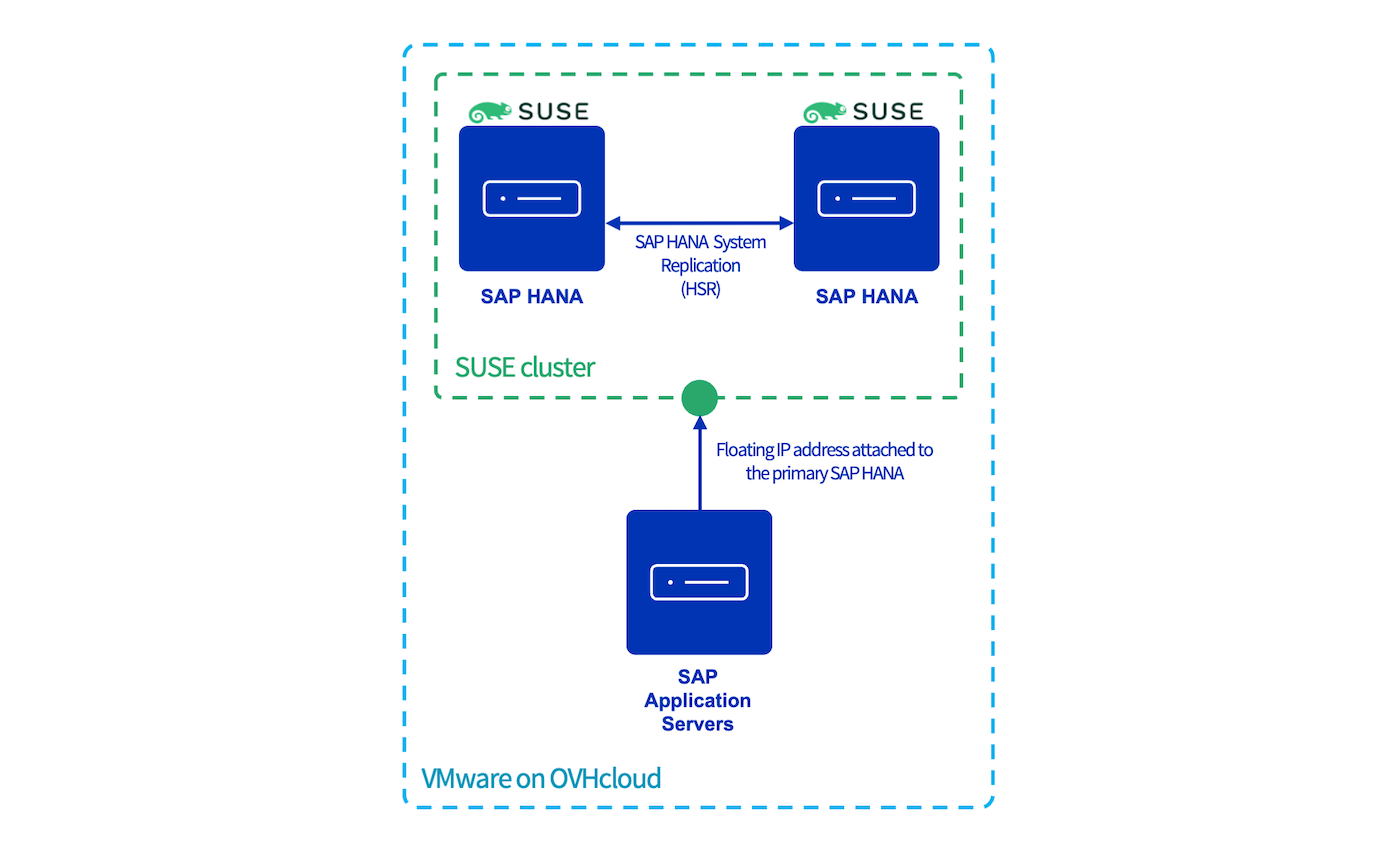
Prérequis
- Un accès à l'espace client OVHcloud.
- Une solution SAP HANA on Private Cloud déployée.
- Deux machines virtuelles SAP HANA déployées ayant la même version SAP HANA installée.
En pratique
Dans tous les blocs de console :
- Le nœud primaire SAP HANA est nommé
node1et le nœud secondaire SAP HANA est nomménode2. <SID>est le SID SAP HANA.<NI>est le numéro d'instance SAP HANA.
La disponibilité de SAP HANA pourrait être affectée durant la configuration. Veillez à prendre toutes les précautions nécessaires avant de suivre les instructions de ce guide.
Utilisateur vSphere
Pour autoriser le service corosync à obtenir les informations des nœuds SAP HANA, vous devez configurer un utilisateur avec les droits d'accès à l'interface vSphere.
Nous recommandons d'utiliser un utilisateur dédié avec des droits limités pour interagir avec vSphere.
Cet utilisateur dédié n'a besoin que du droit en « Lecture seule » sur le datacenter où sont hébergées les machines virtuelles SAP HANA. Pour connaître les étapes de création d'un utilisateur dédié, veuillez vous référer à notre guide.
Paquets SUSE
Plusieurs paquets, incluant les binaires corosync et pacemaker, doivent être installés sur les deux nœuds SAP HANA.
Ces paquets sont uniquement disponibles avec l'extension SUSE Linux Enterprise High Availability. Veuillez vous assurer qu'elle est activée avant de continuer :
- Résultat attendu :
Dans les autres cas, veuillez exécuter la commande suivante dans laquelle <ADDITIONAL REGCODE> est le code d'enregistrement fourni par SUSE dans votre espace client SUSE.
Exécutez les commandes suivantes pour installer les paquets nécessaires :
Préparation de SAP HANA
Sauvegarde
Si vous exécutez cette configuration sur des nouvelles machines virtuelles SAP HANA, vous devez déclencher une sauvegarde du SYSTEMDB et du TENANTDB avant de continuer la configuration sur le futur nœud primaire. Ces sauvegardes sont obligatoires pour activer le système de réplication SAP HANA (HSR).
Python Hook SAPHanaSR
Le provider hook SAP HANA HA/SR améliore la détection d'erreurs SAP HANA.
1. Arrêtez les services SAP HANA sur les deux nœuds :
2. Ajoutez ce bloc dans le fichier global.ini sur les deux nœuds :
Système de réplication
1. Démarrez les services SAP HANA sur le nœud primaire :
2. Avec l'utilisateur SAP HANA (sid)adm, activez le système de réplication SAP HANA (HSR) sur le nœud primaire qui sera la source de la réplication :
L'option --name est obligatoire et est utilisée pour définir le nœud SAP HANA dans le système de réplication.
3. Pour autoriser le nœud secondaire à s'enregistrer sur le nœud primaire, vous devez transférer deux fichiers du nœud primaire sur le nœud secondaire :
- /usr/sap/
<SID>/SYS/global/security/rsecssfs/data/SSFS_<SID>.DAT - /usr/sap/
<SID>/SYS/global/security/rsecssfs/key/SSFS_<SID>.KEY
4. Une fois ces fichiers transférés sur le nœud secondaire, vous pouvez enregistrer le nœud secondaire sur le nœud primaire :
Pour connaître les différences entre les modes de réplication et d'opération, nous vous recommandons la documentation SAP.
Dans le cadre de notre guide, les deux nœuds SAP HANA sont hébergés sur la même localisation OVHcloud, nous recommandons d'utiliser les paramètres suivants :
| Paramètre | Valeur |
|---|---|
| replicationMode | sync |
| operationMode | logreplay |
5. Démarrez les services SAP HANA sur le nœud secondaire. Le démarrage des services SAP HANA déclenche l'initialisation de la réplication du nœud primaire vers le nœud secondaire :
Sur le nœud primaire, vous pouvez suivre l'initialisation de la réplication avec la commande suivante :
La réplication peut prendre un certain temps, cela dépend du volume de données dans votre base de données SAP HANA. Une fois l'initialisation de la réplication terminée, le statut du système de réplication doit être ACTIVE.
Corosync
Dans ce chapitre, toutes les commandes doivent être exécutées en tant que root.
1. Sur le nœud primaire, générez le fichier /etc/corosync/authkey :
Ce fichier est la clef privée qui garantit l'authenticité et le chiffrement des messages échangés entre les nœuds du cluster.
2. Créez le fichier /etc/corosync/corosync.conf sur le nœud primaire et ajoutez la configuration suivante (remplacez <ip_address_node1> et <ip_address_node2> par vos adresses IP) :
Pour découvrir tous les paramètres de configuration, veuillez vous référer au manuel corosync.conf.5 avec la commande man corosync.conf.5.
3. Transférez ces fichiers sur le nœud secondaire pour partager la configuration et la clef privée :
Pacemaker
1. Démarrez les services corosync et pacemaker sur les deux nœuds :
2. Nous conseillons de retarder le démarrage du service corosync lors du démarrage de la machine virtuelle.
a. Éditez le service corosync sur les deux nœuds :
b. Insérez ces lignes entre les lignes 3 et 6 :
c. Rechargez la configuration :
d. Si la configuration a été correctement chargée, la ligne -override.conf apparaît dans le statut du service corosync :
e. Assurez-vous que les services corosync et pacemaker démarrent automatiquement durant le démarrage de la machine virtuelle :
3. Sur le nœud primaire, configurez les propriétés générales du cluster SUSE pour SAP HANA :
4. Sur le nœud primaire, activez le mode maintenance du cluster :
Ressource stonith
Les actions qui vont suivre doivent être réalisées sur le nœud primaire.
La ressource stonith vérifie l'état de santé des machines virtuelles à travers vSphere et peut décider d'éteindre la machine virtuelle.
L'identifiant et le mot de passe sont les identifiants créés dans le chapitre « Créer un utilisateur vSphere ».
- Résultat attendu :
Ressource adresse IP flottante
La ressource res_vip_<SID>_HDB<NI> gère et surveille l'adresse IP flottante qui est le point d'entrée des communications avec le nœud primaire.
<floating_ip_address>est l'adresse IP flottante qui sera utilisée par le cluster.- Si vous avez plusieurs cartes réseau, vous pouvez spécifier la carte réseau en ajoutant le paramètre
nic.
- Résultat attendu :
Ressources SAP HANA
1. La ressource rsc_SAPHana_<SID>_HDB<NI> gère et surveille les services SAP HANA sur les deux nœuds.
Pour découvrir tous les paramètres de cette ressource, veuillez vous référer au manuel ocf_suse_SAPHana avec la commande man ocf_suse_SAPHana.
2. La ressource rsc_SAPHanaTopology_<SID>_HDB<NI> surveille la réplication SAP HANA.
- Résultat attendu :
Pour découvrir tous les paramètres de cette ressource, veuillez vous référer au manuel ocf_suse_SAPHanaTopology avec la commande man ocf_suse_SAPHanaTopology.
Si la ressource rsc_SAPHana_<SID>_HDB<NI> est affichée en échec même si les services SAP HANA sont correctement actifs, exécutez la commande suivante pour rafraîchir le statut :
crm resource refresh
3. Pour éviter un comportement inattendu, nous vous conseillons de désactiver les ressources rsc_SAPHana_<SID>_HDB<NI> et rsc_SAPHanaTopology_<SID>_HDB<NI>
4. Quittez le mode maintenance :
5. Rafraîchissez le cluster sur le nœud primaire :
6. Activez les ressources précédemment désactivées à l'étape 3 :
- Résultat attendu après plusieurs secondes :
L'adresse IP flottante est attachée sur la carte réseau :
7. Créez le fichier /etc/sudoers.d/SAPHanaSR-srHook et ajoutez le contenu suivant sur les deux nœuds :
- Pour obtenir le nom du siteA et du siteB, exécutez la commande
crm status -A1 | grep site. <sid>est le SID SAP HANA en minuscule.
Test de bascule
Pour valider la configuration et son comportement, nous recommandons d'exécuter un test de bascule.
Vous pouvez simuler la perte d'un nœud SAP HANA de différentes manières :
- Arrêter la machine virtuelle sur vSphere
- Arrêter la machine virtuelle avec la commande OS
- Arrêter les services SAP HANA avec la commande OS
- Éteindre la carte réseau
- Simuler la perte d'un hôte ESXi avec l'API OVHcloud
- Mettre en veille le nœud primaire dans le cluster
Perte du nœud SAP HANA primaire
Dans ce cas, le comportement attendu est la bascule de toutes les ressources hébergées sur le nœud primaire vers le nœud secondaire qui deviendra le nœud primaire.
Le node1 est vu comme Master et le node2 comme Slave.
Toutes les ressources sont correctement gérées et surveillées par le cluster.
Le cluster détecte la perte du node1 qui était le Master et déclenche la bascule sur le node2.
La bascule peut prendre plusieurs minutes, cela dépend du volume de la base de données SAP HANA.
Le node2 est maintenant vu comme le nouveau Master et le node1 est vu comme déconnecté.
Une fois le problème réglé sur le node1, vous devez enregistrer le node1 vers le node2 et démarrer les services SAP HANA pour restaurer le cluster dans un état nominal.
Perte du nœud secondaire SAP HANA
Dans ce cas, le comportement attendu est uniquement la détection de la perte du nœud secondaire, aucune action ne doit être réalisée par le cluster.
Le node1 est vu comme Master et le node2 comme Slave.
Toutes les ressources sont correctement gérées et surveillées par le cluster.
Le node2 est vu comme déconnecté. Comme le nœud était Slave, aucune action n'a été réalisée par le cluster.
Une fois le problème réglé sur le node2, démarrez les services SAP HANA pour restaurer le cluster dans un état nominal.
Aller plus loin
Si vous avez besoin d'une formation ou d'une assistance technique pour la mise en oeuvre de nos solutions, contactez votre commercial ou cliquez sur ce lien pour obtenir un devis et demander une analyse personnalisée de votre projet à nos experts de l’équipe Professional Services.
Échangez avec notre communauté d'utilisateurs.

