Object Storage - Optimiser les performances
179 vues
Objectif
Il existe plusieurs façons d'optimiser les performances de vos buckets sur l'Object Storage.
Le guide suivant vous présente les différentes méthodes d'optimisation.
Utilisation de la recherche par plage d'octets
OVHcloud Object Storage prend en charge l'extraction de plage d'octets. L'idée est de récupérer un objet morceau par morceau, chaque morceau étant défini par une plage d'octets.
Le principal avantage est qu'il vous permet de paralléliser les requêtes GET pour télécharger un objet, chaque requête GET demandant une plage d'octets spécifique : les tailles typiques des requêtes de plage d'octets sont de 8 Mo ou 16 Mo, mais vous pouvez spécifier n'importe quelle taille.
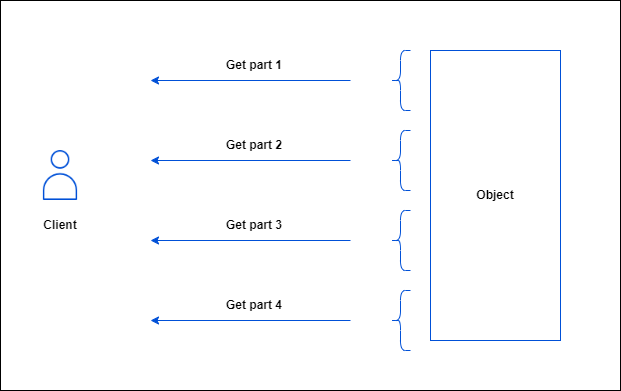
Pour télécharger une partie d'un objet, vous devez utiliser des paramètres supplémentaires pour spécifier la partie de l'objet à récupérer. L'exemple suivant télécharge la première partie, comprise entre 0 et 500 octets, d'un objet nommé <object_key> stocké dans le bucket <bucket_name> et écrit la sortie dans un fichier nommé object_part :
Utilisation des MPU
Vous pouvez télécharger un objet unique sous la forme d'une collection d'articles à l'aide des téléversements en plusieurs parties (multipart uploads). Ces parties peuvent être téléchargées séparément et dans n'importe quelle séquence. Vous pouvez retransmettre une pièce sans affecter les autres en cas d'échec de la transmission d'une pièce. Une fois toutes les pièces téléchargées, OVHcloud Object Storage les assemble et reconstruit l'objet.
Pensez à utiliser des téléversements en plusieurs parties (multipart uploads) pour les objets > 100MB
Les avantages des *multipart uploads- sont les suivants :
- Débit accru : chaque partie peut être uploadée simultanément.
- Récupération rapide en cas de problème réseau : chaque partie pouvant être uploadée séparément et indépendamment, vous pouvez re-uploader la partie manquante sans redémarrer l'upload complet.
En pratique
Via AWS CLI
Vous aurez besoin des éléments suivants :
- Avoir créé un bucket OVHcloud
- Avoir installé et configuré AWS CLI
- Avoir un fichier volumineux divisé en plusieurs parties
Le saviez-vous ?
Lorsque vous utilisez une commande de haut niveau pour uploader un objet à l'aide de la commande cp, AWS CLI effectue automatiquement un multipart upload. Pour optimiser les valeurs de configuration par défaut pour les *multipart uploads- (multipart_threshold, multipart_chunksize), vous pouvez consulter cet article et voir le tableau expliquant comment configurer AWS CLI.
La section suivante explique comment effectuer un multipart upload* à l'aide des commandes de bas niveau du AWS CLI.
Tout d'abord, vous devez lancer un multipart upload* :
N'oubliez pas de sauvegarder les upload ID, key et bucket name pour les utiliser avec la commande upload-part.
Pour chaque partie, vous devez exécuter la commande upload-part dans laquelle vous spécifiez les bucket, key- et upload ID- :
Les numéros de référence peuvent être compris entre 1 et 10 000 inclus. Vous pouvez vérifier les limitations techniques ici.
Enregistrez la valeur ETag- de chaque article pour plus tard. Elles sont nécessaires pour terminer le multipart upload*.
Une fois toutes les pièces téléchargées, vous devez exécuter la commande complete-multipart-upload pour terminer le processus et pour que le OVHcloud Object Storage reconstruise l'objet final :
Où mpu.json est :
Si le multipart upload n'est pas terminé, l'objet final ne sera pas assemblé et restera invisible. Néanmoins, toutes les pièces téléchargées restent stockées et entraînent des frais de stockage.
Pour éviter des coûts inutiles, vous pouvez interrompre le multipart upload à l'aide de la commande CLI AWS suivante :
L'ID de l'upload est renvoyé par la commande create-multipart-upload ou peut être récupéré en listant les multipart uploads en cours :
Exemple d'interruption d'un multipart upload spécifique après avoir récupéré son ID d'upload :
Via d'autres outils tiers
La liste suivante décrit les options permettant d'effectuer des multipart uploads* à l'aide d'autres outils. La liste n'est pas exhaustive car vous pouvez également vérifier la documentation appropriée pour l'outil que vous utilisez.
s3cmd
Cette commande représente la taille de chaque segment d'un multipart upload.
Les fichiers supérieurs à SIZE sont automatiquement téléchargés en tant que fichiers multithread-multipart.Les fichiers plus petits sont téléchargés à l'aide de la méthode traditionnelle.
SIZE est exprimé en méga-octets, la taille de bloc par défaut est de 15 Mo, la taille de bloc minimale autorisée est de 5 Mo, la taille maximale est de 5 Go.
Exemple :
Pour plus d'informations sur s3cmd, consultez la documentation officielle ici.
rclone
Cette commande représente le seuil de taille à partir duquel rclone passe d'un upload d'un fichier unique au multipart upload.
Cette commande représente la taille de chaque segment utilisé dans les multipart uploads.
Cette commande représente le nombre de segments uploadés simultanément.
Exemple :
Pour plus d'informations sur rclone, consultez la documentation officielle.
Augmentation du nombre de demandes simultanées
Une autre façon d'améliorer le débit est d'augmenter le nombre de demandes simultanées.
Pour personnaliser la valeur par défaut sur AWS CLI, consultez ce guide.
Pour les autres outils, nous vous invitons à consulter la documentation du logiciel utilisé.
Optimisation I/O
Il est également possible d’optimiser considérablement les performances en adoptant de bonnes pratiques pour répartir les I/O le plus largement possible dans le cluster de stockage d’objets, en tirant parti du mécanisme de fragmentation (sharding).
Qu’est-ce que le *sharding- ?
OpenIO est une solution de Software-Defined Storage sur laquelle repose l’Object Storage d’OVHcloud.
Dans OpenIO, un conteneur- est essentiellement une entité logique interne qui contient tous les objets d'un bucket donné. Chaque conteneur est associé à une base de données de métadonnées interne qui répertorie toutes les adresses du cluster des objets qu'il contient. Par défaut, un bucket Object Storage est associé à un conteneur, mais cela peut changer avec le mécanisme de sharding*.
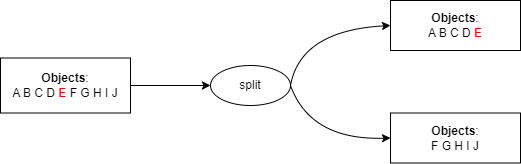
Le sharding est le mécanisme par lequel un conteneur est divisé en 2 nouveaux sous-conteneurs (et donc sa base de données de métadonnées associée est également divisée en 2) lorsqu'il atteint un nombre critique d'objets appelé shards.
Le *sharding- permet :
- d'optimiser les opérations de lecture/écriture en les répartissant uniformément sur plusieurs serveurs (shards).
- de répartir le stockage des données sur l'ensemble du cluster pour augmenter la résilience.
Nous utilisons les clés d'objet (préfixe/nom) pour déterminer quels objets sont poussés dans quel sous-conteneur en utilisant la logique suivante :
- Créer 2 nouveaux shards.
- Recherche la valeur médiane d'une liste de toutes les clés d'objet triées par ordre alphabétique.
- Copier le contenu du conteneur racine dans les shards.
- Dans le premier shard, ne conserver que la première moitié des objets (de l'objet avec la première clé de la liste à l'objet avec une clé égale à la valeur médiane) et nettoyer la seconde moitié.
- Dans le second shard, ne conserver que la seconde moitié des objets et nettoyer la première moitié.
- Le conteneur racine ne liste alors que les références aux shards, c'est-à-dire quelle plage d'objets dans quel shard.
Cette logique peut se résumer ainsi :
Les bonnes pratiques du préfixe
Vous pouvez optimiser les I/O sur le cluster en profitant des mécanismes de sharding décrits ci-dessus.
La stratégie principale est de garder la cardinalité des clés d'objet à gauche, c'est-à-dire d'utiliser des préfixes qui permettent au sharding de diviser les objets entrants aussi uniformément que possible.
Considérons un cas d'utilisation où vous souhaiteriez stocker des logs dans un Object Storage OVHcloud.
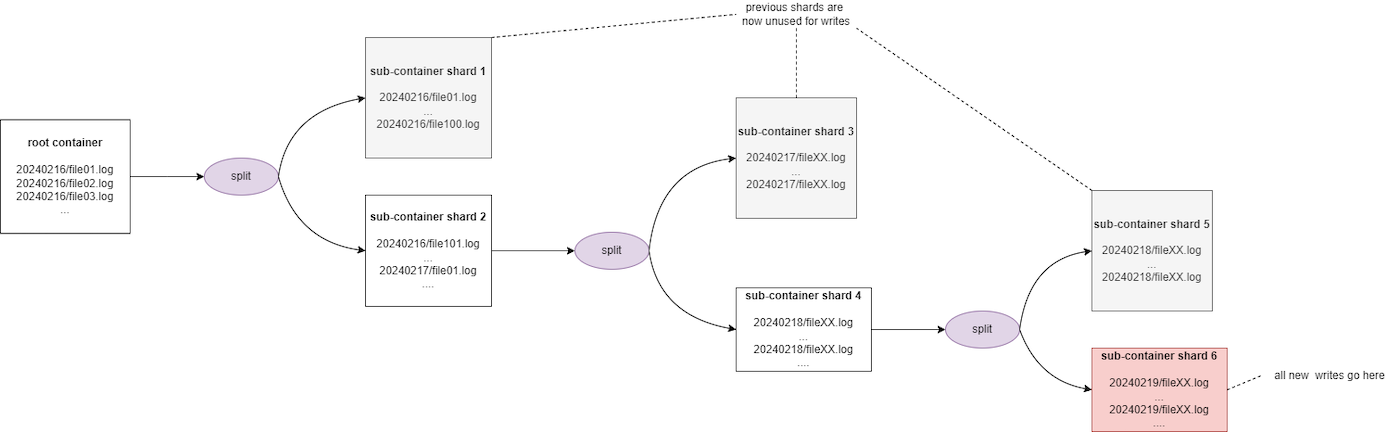
Scénario 1 - Mauvaise pratique en utilisant la date comme préfixe
Liste des objets :
- 20240216/file01.log
- 20240216/file02.log
- 20240216/file03.log
- ...
- 20240217/file01.log
- 20240217/file02.log
- ...
En supposant un seuil de 100, après le téléchargement du 100ème objet, le sharding est déclenché pour diviser les objets en deux fragments :
- de 20240216/file01.log à 20240216/file100.log dans le premier shard
- à partir de 20240216/file101.log et au-delà vers un second shard
Cette solution n'est pas optimale car, les dates étant par nature incrémentales, tous les nouveaux téléchargements seront toujours effectués sur le second shard, qui sera à nouveau fractionné lorsqu'il atteindra une taille critique. Ainsi, toutes les opérations d'écriture futures seront toujours effectuées sur le dernier shard créé et les shards précédents seront rarement utilisés. En outre, vous pouvez rencontrer une certaine limitation pendant le processus de sharding.
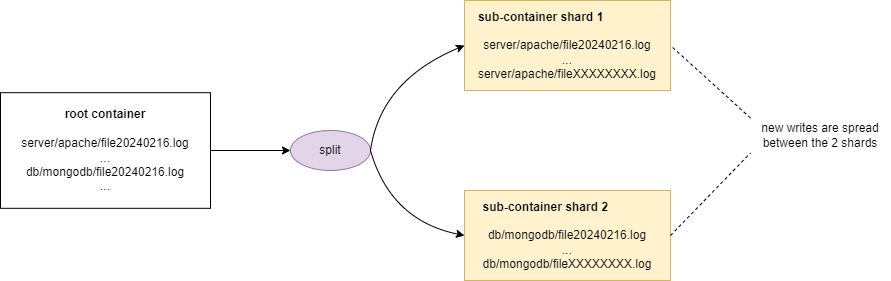
Scénario 2 - Bonne pratique pour maintenir la cardinalité à droite
Liste des objets :
- server/apache/file20240216.log
- server/apache/file20240217.log
- server/apache/file20240218.log
- ...
- db/mongodb/file20240216.log
- db/mongodb/file20240217.log
- ...
En supposant un seuil de 100, après le téléchargement du 100ème objet, le sharding est déclenché pour fractionner les objets en 2 shards. Ce deuxième scénario est optimal car tous les nouveaux uploads seront répartis sur les 2 shards.
Optimiser le temps de montée en charge
Lorsque vous chargez un très grand nombre d'objets à la fois, vous déclenchez le mécanisme de fragmentation (sharding). Au cours du processus de fragmentation, vous pouvez rencontrer une certaine limitation.
Afin d'éviter la baisse de performance (erreurs 503 SLOWDOWN), nous vous recommandons d'optimiser vos uploads en étalant votre requête dans le temps. Cet écart n'a pas à être linéaire, mais il doit nous donner suffisamment de temps pour équilibrer votre charge de travail.
Un moyen simple d'y parvenir consiste à améliorer la gestion des erreurs 503 SLOWDOWN et la récupération des erreurs : augmentez vos uploads jusqu'à ce que vous atteigniez des erreyrs 503 et modulez votre charge de travail pour accommoder la limitation jusqu'à ce que le sharding soit terminé, puis augmentez à nouveau.
Augmenter la taille des objets
Les objets sont considérés comme petits s'ils ont une taille inférieure à 1 Mo. Lorsqu'il s'agit de grands volumes de données (à l'échelle du Po), le nombre total d'objets atteint rapidement des milliards, voire des trillions. Gérer l’administration des métadonnées à cette échelle et le nombre d’opérations d’I/O représente un défi majeur : comment fournir un service de qualité sans perdre d’informations ni compromettre les performances ?.
Le cas échéant, nous vous recommandons d'augmenter autant que possible la taille de l'objet/de la pièce afin de réduire le nombre d'objets.
Aller plus loin
Si vous avez besoin d'une formation ou d'une assistance technique pour la mise en oeuvre de nos solutions, contactez votre commercial ou cliquez sur ce lien pour obtenir un devis et demander une analyse personnalisée de votre projet à nos experts de l’équipe Professional Services.
Échangez avec notre communauté d'utilisateurs.

