AI Deploy - Tutoriel - Déployer des modèles Text-to-Image FLUX (EN)
56 vues
AI Deploy is covered by OVHcloud Public Cloud Special Conditions.
Introduction
FLUX is a flexible family of generative models developed by Black Forest Technologies. The FLUX models support a variety of tasks, including text-to-image generation, structural conditioning, and inpainting.
In this tutorial, we walk through the process of deploying FLUX models on AI Deploy. We will show how to use FLUX models interactively with ComfyUI (a visual programming interface).
Instructions
You are going to follow different steps to deploy your FLUX model:
- Choose the right FLUX variant based on your use case
- Download model weights and store them in OVHcloud Object Storage
- Build a Docker image with ComfyUI and required dependencies
- Deploy app
- Run inference with ComfyUI
Selecting the FLUX Model Variant
FLUX is available in several variants, each tailored to specific use cases, from text-to-image inference to advanced image editing. These variants differ in memory requirements, performance, and licensing terms.
The following table lists the main FLUX variants and their intended use cases:
| Name | Usage | HuggingFace repo | License |
|---|---|---|---|
FLUX.1 [schnell] | Text to Image | Schnell repo | apache-2.0 |
FLUX.1 [dev] | Text to Image | Dev repo | FLUX.1-dev Non-Commercial License |
FLUX.1 Kontext [dev] | Image editing | Kontext repo | FLUX.1-dev Non-Commercial License |
Full list is available on the official repository for FLUX.1 models.
Requirements
Before proceeding, ensure you have the following:
- Access to the OVHcloud Control Panel
- An AI Deploy Project created inside a Public Cloud project in your OVHcloud account
- A user for AI Training & Object Storage
- The OVHcloud AI CLI installed on your computer
- Docker installed on your computer, or access to a Debian Docker Instance, which is available on the Public Cloud
- A Hugging Face account, with access to the FLUX model. You need to accept usage terms on the model Hugging Face page.
- A Hugging Face access token (generate one under your Hugging Face account → Access Tokens). This one will be used to authenticate and download the model weights.
Downloading model weights in OVHcloud Object Storage
To run inference on AI Deploy, you will first need to download the model weights from Hugging Face and upload them to an OVHcloud Object Storage bucket. This bucket will later be mounted into your AI Deploy app at runtime, allowing you to access the downloaded model.
Rather than downloading and uploading files manually, we will automate this process by launching a short AI Training job. This job will:
- Authenticate to Hugging Face using your token
- Create a bucket
- Import packages
- Download the required model weights
- Store them into the created Object Storage bucket
To launch this job, run the following ovhai command in your terminal, replacing with your actual token:
This command will:
- Launch a job based on the
ovhcom/ai-training-pytorchDocker image. - Create (if it doesn't already exist) a bucket named
flux-schnell,flux-devorflux-kontextdepending on the FLUX variant you use, and mount it at/workspace/flux-model. - Install the
huggingface_hublibrary. - Download the FLUX model and its text encoder using
huggingface-cli download. - Save model files into the mounted Object Storage bucket.
- Clean up local Hugging Face caches.
You can track the progress of your job using the following commands:
This will allow you to view the logs generated by your job, seeing the imports and file downloads (might take few minutes to download large model files). Once the model weights are downloaded, the job will enter a FINALIZING state if you list your existing jobs. This means the files are being synced to the mounted Object Storage bucket. When the sync is complete, the job will be marked as DONE.
You can then verify the presence of your files by checking your Object Storage bucket from the OVHcloud Control Panel or via CLI using the following command:
Build a Docker image
Once the FLUX model weights are uploaded to Object Storage, the next step is to build a Docker image that packages ComfyUI and its required dependencies.
This image will later be deployed as an AI Deploy application, where the model files will be mounted at runtime from Object Storage. This avoids the need to embed large model weights directly into the container image.
Create the Dockerfile
In a new folder, create the following Dockerfile. This builds a CUDA environment for ComfyUI:
Add the entrypoint.sh script
This script sets up symbolic links to the mounted model files at runtime, ensuring that ComfyUI finds the downloaded model weights. Indeed, ComfyUI expects the models in specific folders, inside /app/ComfyUI/models.
By linking the models from /workspace (where the object storage will be mounted) to ComfyUI expected locations, we avoid redundant file copies and keep the image lightweight.
Depending on the FLUX variant, files and expected locations might change. This script adapts the locations, regardless of which version you are using between Schnell, Dev, and Kontext.
Build the Docker Image
Then, launch one of the following commands from the created folder that contain your Dockerfile and the entrypoint.sh script to build your application image:
-
The first command builds the image using your system’s default architecture. This may work if your machine already uses the
linux/amd64architecture, which is required to run containers with our AI products. However, on systems with a different architecture (e.g.ARM64onApple Silicon), the resulting image will not be compatible and cannot be deployed. -
The second command explicitly targets the
linux/AMD64architecture to ensure compatibility with our AI services. This requiresbuildx, which is not installed by default. If you haven’t usedbuildxbefore, you can install it by running:docker buildx install
Push the image to a registry
After building the image, tag and push it to a container registry.
In this example, we use the OVHcloud shared registry, available to every AI Deploy user. But you can also use other registires such as OVHcloud Managed Private Registry, Docker Hub, GitHub packages, etc.
The shared registry should only be used for testing purpose. Please consider attaching your own registry. More information about this can be found here. The images pushed to this registry are for AI Tools workloads only, and will not be accessible for external uses.
You can find the address of your shared registry by launching this command:
Log in to the shared registry with your usual AI Platform user credentials:
Tag the compiled image and push it into your registry:
Deploy app
With your Docker image built and model weights available in Object Storage, you are now ready to deploy your application on AI Deploy.
Run the following command to deploy your application:
```sh ovhai app run /flux-image:latest \ --name flux-dev-app \ --gpu 1 \ --flavor ai1-1-gpu \ --default-http-port 8188 \ --volume flux-dev@GRA/:/workspace/flux-model:RO \ --env FLUX_VARIANT=base \ --env BUCKET_MOUNT_PATH=/workspace/flux-model \ --env UNET_FILE=flux1-dev.safetensors \ --env VAE_FILE=ae.safetensors \ --env CLIP_FILE_1=clip_l.safetensors \ --env CLIP_FILE_2=t5xxl_fp16.safetensors
Parameters Explained
<registry_address/flux-image:latest: The image to deploy. Make sure to use your registry address.--name: Sets the app name,flux_apphere.--gpu: Number of GPUs requested.--flavor: The type of GPU requested. Theai1-1-gpuflavor code corresponds to aV100SGPU. To view other GPUs available, runovhai capabilities flavor list. Feel free to change flavor code to another one.--default-http-port 8188: Default HTTP port of the app. ComfyUI listens on port8188.--volume: Mounts downloaded model files from Object Storage. In this case, theflux-modelbucket is mounted read-only at/workspace/flux-model.--env: Sets environment variables used byentrypoint.shto configure the FLUX model files symlinks.
Other FLUX variants may expect files in different folders. If you plan to use another variant, make sure to also update the environment variables to match this variant, and adjust the entrypoint.sh script if necessary to match new files and folder structures.
Once you launch the app, AI Deploy will execute the following phases:
- Image Pull Phase: Downloads the Docker image from your registry.
- Data Sync Phase: Mounts the Object Storage volume and makes the model files available.
- Runtime Phase: Starts the container, runs your
entrypoint.sh, and launches ComfyUI interface.
To monitor your app progress and logs in real time, use:
Once you see in the logs that ComfyUI has started and is listening on port 8188, the app is ready to use. You can access the interface using the public URL provided by the platform, such as:
You can retrieve it at any time using the following commands:
Run inference with ComfyUI
Once inside the ComfyUI web interface, head to the official ComfyUI FLUX examples page. Find the image matching your deployed variant.
Then, drag and drop this image into your ComfyUI interface. This will automatically load the FLUX image workflow.
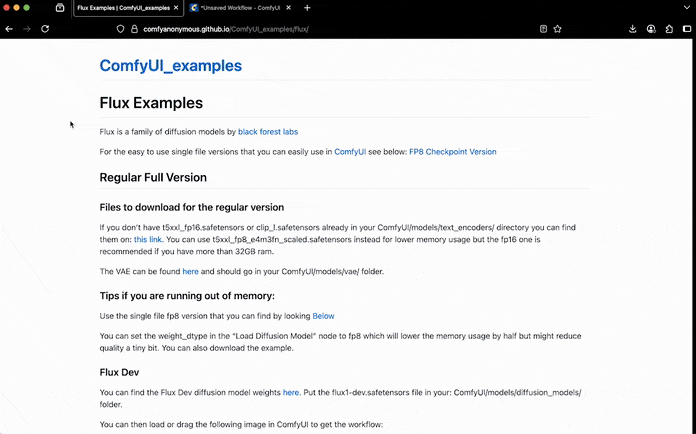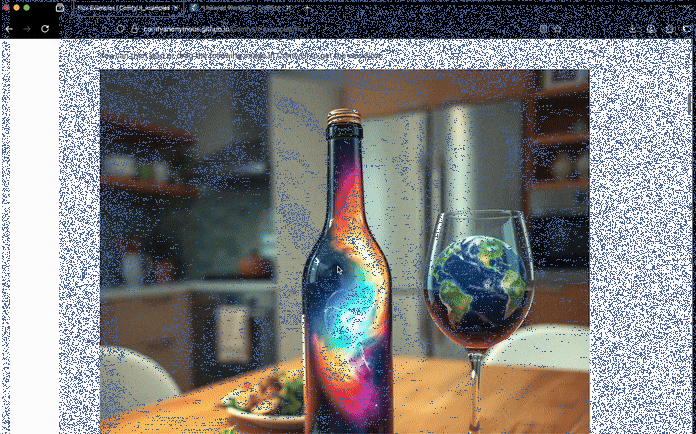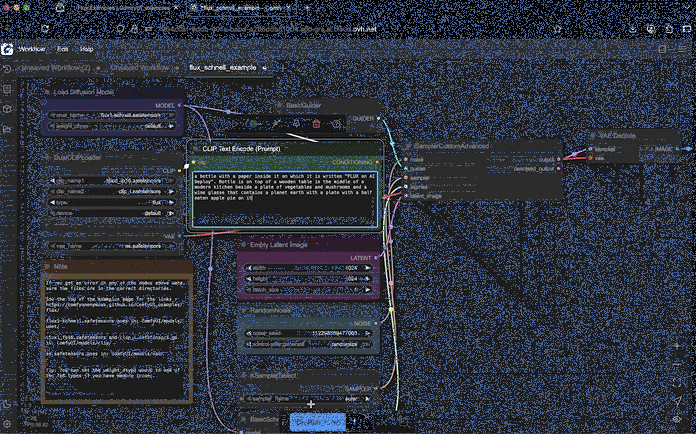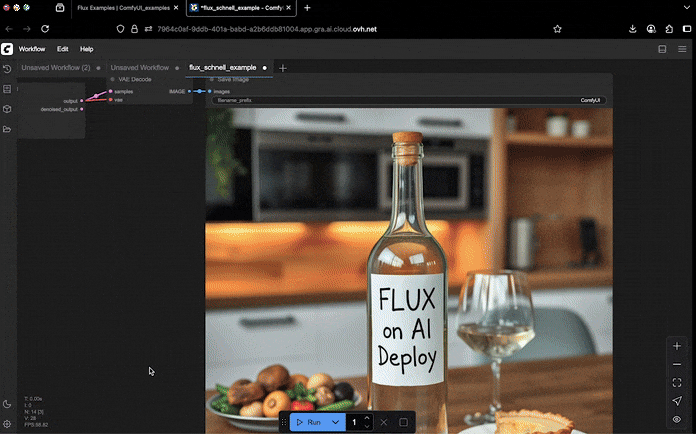
You can now customize the text prompt or parameters as desired. Then, just click the Run button to start the image generation or editing process.
Once the image is generated, you can view and download it directly from the ComfyUI output node.
Go further
If you want to deploy a different interface such as AUTOMATIC1111 with Stable Diffusion XL, we have a step-by-step guide to deploy this popular Web UI on AI Deploy.
If you are interested in image generation concepts, you can learn how image generation networks work and train your own Generative Adversarial Network. Check out this AI Notebooks guide: Create and train an image generation model.
If you need training or technical assistance to implement our solutions, contact your sales representative or click on this link to get a quote and ask our Professional Services experts for a custom analysis of your project.
Feedback
Please send us your questions, feedback and suggestions to improve the service:
- On the OVHcloud Discord server

