VMware HA (High Availability)
259 vues
Objectif
La fonction principale de VMware HA (High Availability) en cas de défaillance matérielle est de redémarrer les machines virtuelles sur un autre hôte du cluster. HA permet aussi de surveiller les VMs ainsi que les applications.
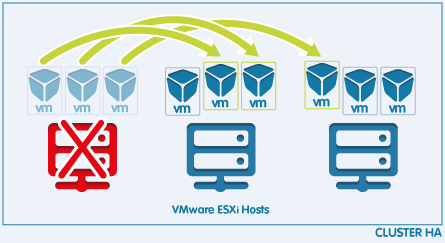
Ce guide explique le paramètrage de cette fonction
Prérequis
- Être connecté à votre interface vSphere.
- Posséder un produit Managed Bare Metal.
En pratique
Activation
HA est activé par défaut dans le cluster de base que OVHcloud vous fournit lors de la livraison de votre Managed Bare Metal.
En cas de création d'un nouveau cluster, vous pouvez activer HA lors de la création du cluster ou après celle-ci.
Si HA n'est pas activé dans votre cluster, rendez vous dans l'onglet Configure de votre cluster puis sur l'onglet Disponibilité vSphere disponible dans la rubrique Services.
Cliquez sur Modifier et cochez la case pour arctiver la fonctionnalité HA.
Il est également important d'activer la surveillance de l'hôte. Ce paramètre permet l'envoi de signaux de pulsation entre les hôtes ESXi afin de détécter une éventuelle panne. La désactivation est nécessaire pour réaliser des opérations de mise à jour avec l'update manager par exemple. Dans ce cas précis, l'hôte est isolé.
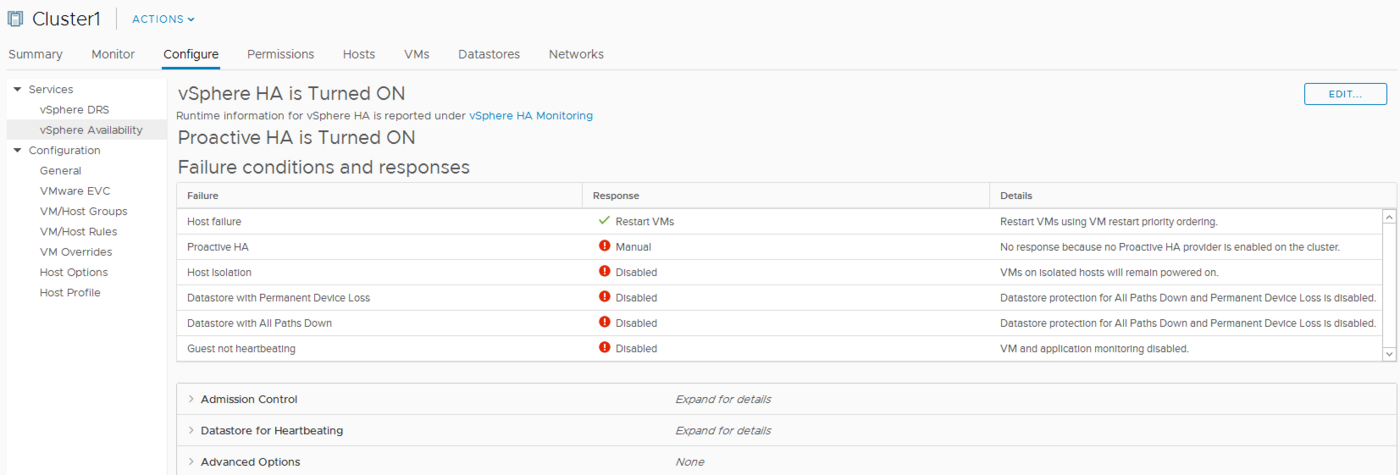
Paramètres
Pannes et réponses
Cette première catégorie permet de définir votre politique de redémarrage des VM en fonction des différentes pannes possibles.
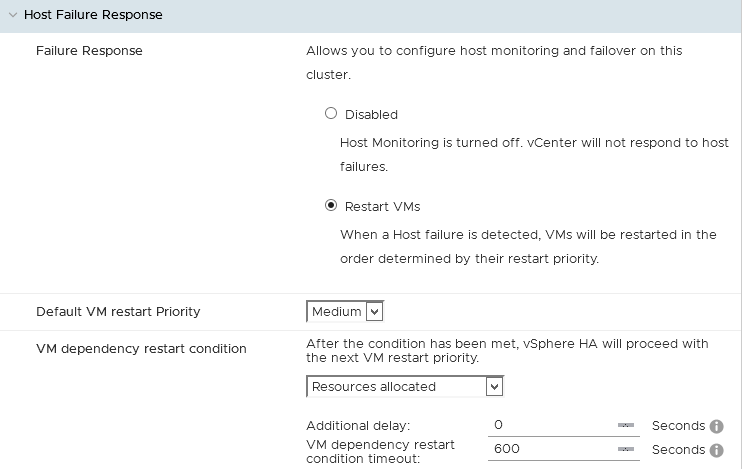
Réponse en cas de panne de l'hôte
Cette catégorie va définir votre politique de redémarrage des VM en cas de perte d'un hôte.
Ainsi, vous pouvez choisir de redémarrer vos machines virtuelles automatiquement ou non.
Une gestion de redémarrage par défaut sur le cluster est également possible. Vous pouvez affiner cela par machine virtuelle dans l'onglet Remplacements VM.
Vous pouvez également séléctionner une condition, autre que celle par défaut (Ressources allouées), que vSphere HA va vérifier avant de procéder au redémarrage.
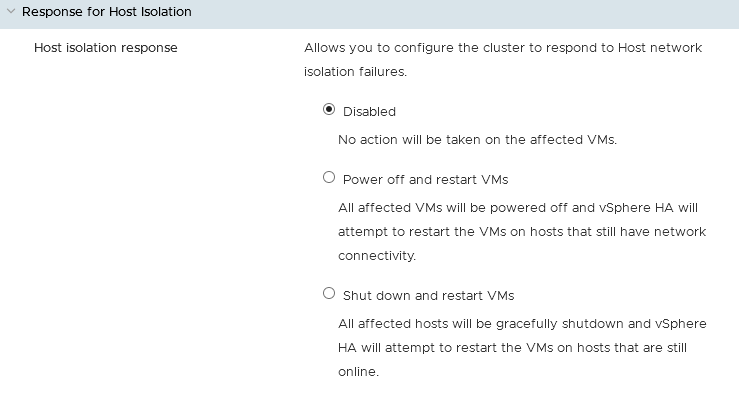
Réponse à l'isolation d'hôte.
Cette catégorie vous permet de définir les actions à entreprendre en cas de perte de connectivité réseau sur un hôte.
Vous pouvez au choix :
- Ne rien faire.
- Mettre hors tension les machines virtuelles et tenter un redémarrage de celles ci sur un autre hôte disponible.
- Eteindre l'hôte concerné et tenter un redémarrage des machines virtuelles sur un autre hôte disponible.
Banque de données avec PDL
En cas de défaillance d'une banque de données avec un état PDL (permanent device loss) vous pouvez définir les actions à entreprendre :
- Ne rien faire.
- Ne rien faire, mais générer des logs dans les évenements.
- Mettre hors tension les machines virtuelles et tenter un redémarrage de celles ci sur les hôtes qui ont toujours de la connectivité avec la banque de données.

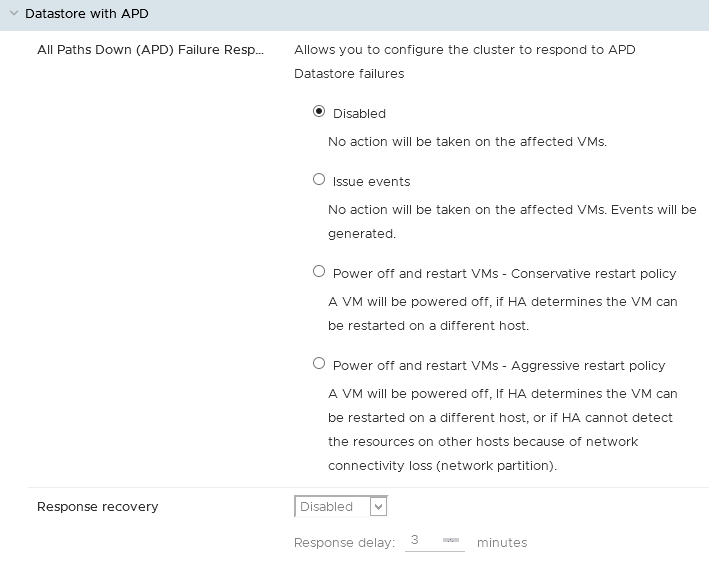
Banque de données avec APD
En cas de défaillance d'une banque de données avec un état APD (all path down) vous pouvez définir les actions à entreprendre :
- Ne rien faire.
- Ne rien faire, mais générer des logs dans les évenements.
- Mettre hors tension les machines virtuelles et tenter un redémarrage de celles ci.
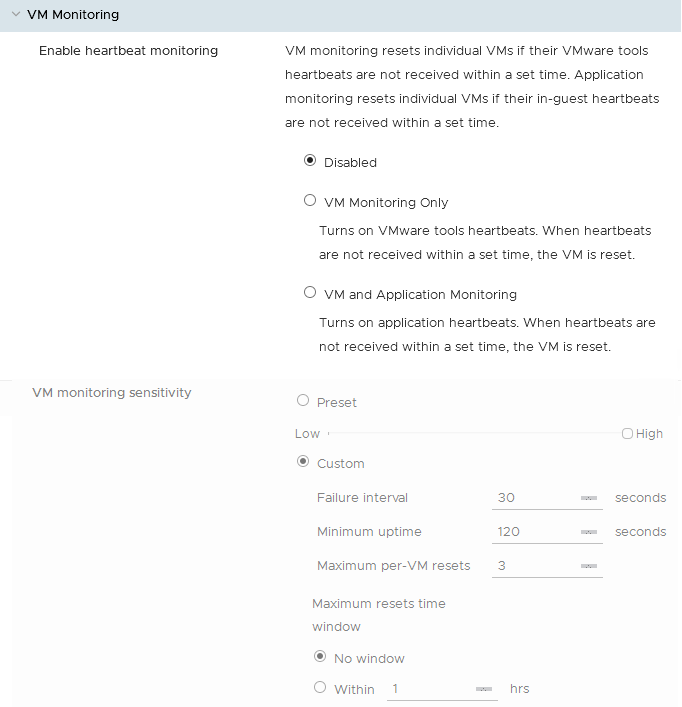
Surveillance de VM
La surveillance des machines virtuelles est disponible suite à l'installation des VMware tools. En cas de non réponse via les tools (signaux de pulsation), la machine virtuelle sera automatiquement redémarrée. Une configuration avancée est possible par rapport à cette fonctionnalité (intervalles de redémarrage par exemple).
Contrôle d'admission
vSphere HA utilise le contrôle d'admission pour s'assurer que des ressources suffisantes sont réservées à la récupération des machine virtuelles en cas de défaillance d'un hôte.
Le contrôle d'admission impose des contraintes sur l'utilisation des ressources. Les actions qui risquent d'enfreindre ces contraintes ne sont pas autorisées. Les actions qui peuvent ne pas être autorisées incluent les exemples suivants :
- Mise sous tension d'une machine virtuelle
- Migration d'une machine virtuelle
- Augmentation de la réserve de CPU ou de mémoire d'une machine virtuelle
La base du contrôle d'admission vSphere HA est le nombre de défaillances d'hôte que le cluster est autorisé à tolérer et qui continue à garantir le basculement. La capacité de basculement des hôtes peut être définie de trois manières différentes :
Banques de données de signal de pulsation
Lorsque l'hôte principal d'un cluster HA ne peut pas communiquer avec un hôte subordonné sur le réseau de gestion, l'hôte principal utilise le signal de pulsation de banque de données pour déterminer si l'hôte subordonné est défaillant, s'il se trouve dans une partition de réseau ou est isolé du réseau.
Options avancées
Plusieurs paramètres de configuration avancée peuvent être utilisés dans votre cluster.
Vous pouvez retrouver des paramètres sur cette page.
Règle HA
Dans la section configuration puis dans l'onglet Règles VM/Hôte, vous pouvez créer une règle de type « Machines virtuelles à machines virtuelles ».
Celle-ci va ajouter une condition de redémarrage afin de s'assurer que des machines virtuelles d'un premier groupe soient toutes démarrées avant de démarrer celles d'un second groupe.
Cette règle peut très bien s'ajouter en complément des priorités de redémarrage paramètrables dans l'onglet Remplacements VM.
Aller plus loin
Échangez avec notre communauté d'utilisateurs.

