VMware HA (High Availability)
514 visualizaciones
Objetivo
La función principal de VMware HA(Alta disponibilidad) es reiniciar las máquinas virtuales en otro host del cluster en caso de fallo del hardware. Con HAtambién se pueden supervisar las máquinas virtuales y las aplicaciones.
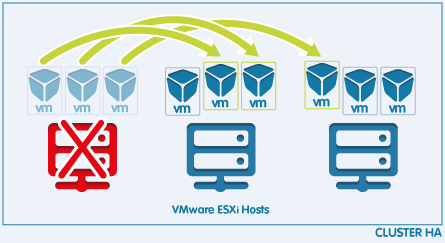
Esta guía explica cómo configurar esta función
Requisitos
- Estar conectado a la interfaz vSphere.
- Tener contratado un Managed Bare Metal de OVHcloud.
Procedimiento
Activación
La funcionalidad HA está activa por defecto en el primer cluster que OVHcloud le proporciona cuando contrata el servicio Managed Bare Metal.
Si se crea un cluster nuevo, se puede activar la funcionalidad HA en el proceso de creación del cluster o posteriormente.
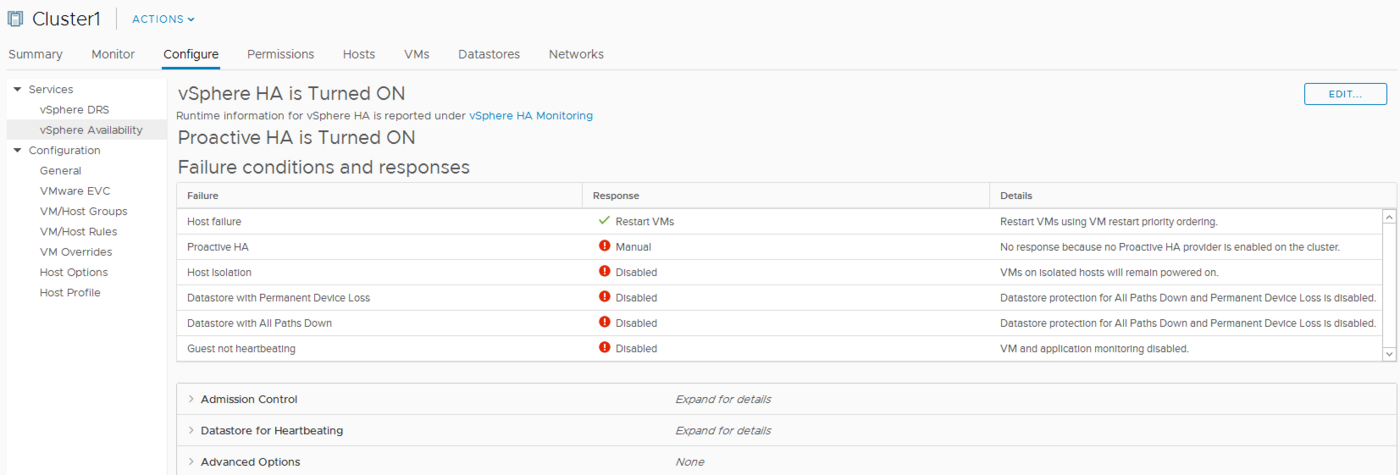
Si HA no está activo en su cluster, diríjase a la pestaña Configure de su cluster, y a la sección Disponibilidad de vSphere en la parte de Servicios.
Haga clic en Editar y marque la casilla para activar la funcionalidad HA.
Es importante activar también la supervisión del host. Esta configuración permite el envío de latidos entre los host ESXi para detectar una posible avería. Será necesario desactivarla para llevar a cabo ciertas tareas como las actualizaciones con el update manager. En ese caso, el host estará aislado.
Configuración
Fallos y respuestas
Esta primera categoría permite definir la política de reinicio de las máquinas virtuales en función de los posibles fallos.
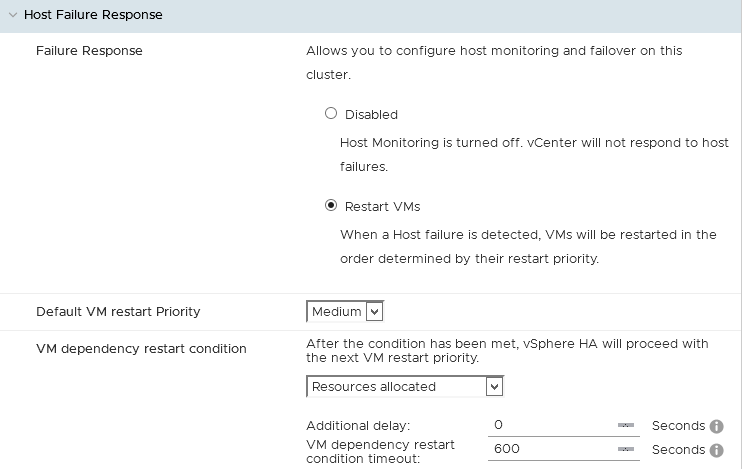
Respuesta en caso de fallo del host
Esta categoría va a definir la política de reinicio de las máquinas virtuales en caso de pérdida de un host.
Es posible definir que se reinicien sus máquinas virtuales de forma automática.
También se puede activar el reinicio por defecto en el cluster. Puede afinar esta configuración por máquina virtual en la pestaña Reemplazo de las MV.
También puede definir una condición diferente a la que viene por defecto (Recursos asignados), que vSphere HA comprobará antes de proceder con el reinicio.
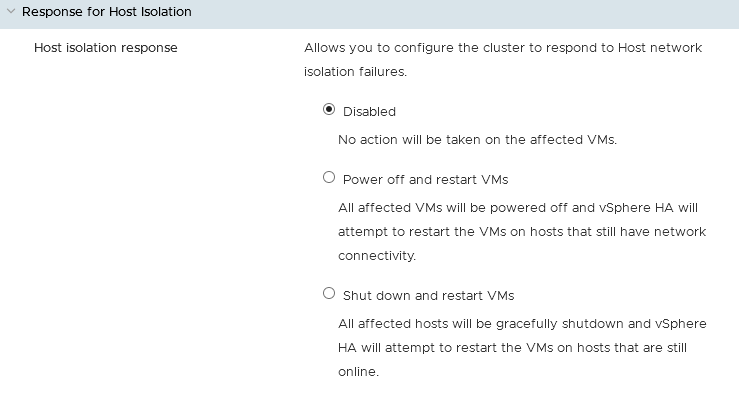
Respuesta al aislamiento del host.
Esta categoría le permite definir las acciones que deben llevarse a cabo en caso de pérdida de conectividad de red en un host.
Puede elegir entre:
- No hacer nada.
- Apagar las máquinas virtuales e intentar reiniciarlas en otro host disponible.
- Apagar el host en cuestión e intentar reiniciar las máquinas virtuales en otro host disponible.
Almacén de datos con PDL
En caso de que falle un almacén de datos con estado PDL (pérdida permanente de dispositivo), se pueden definir las acciones que deben llevarse a cabo:
- No hacer nada.
- No hacer nada pero generar logs de los eventos.
- Apagar las máquinas virtuales e intentar reiniciarlas en los host que siguen teniendo conectividad con el almacén de datos.

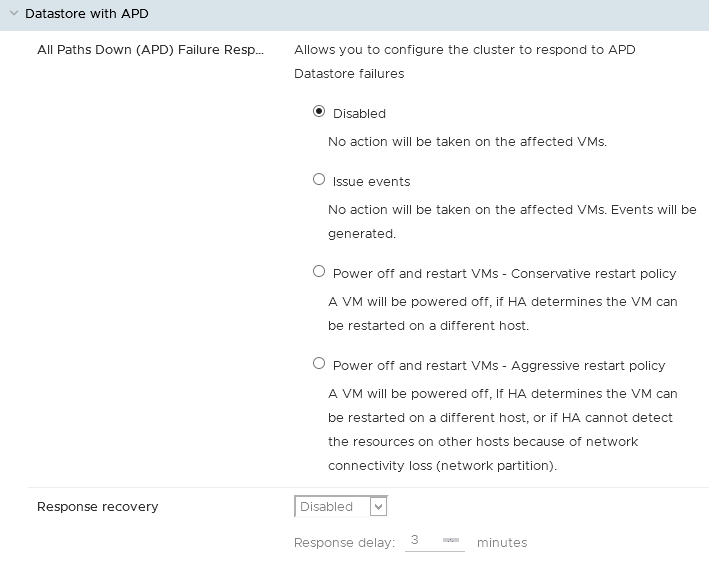
Almacén de datos con APD
En caso de que falle un almacén de datos con estado APD (all path down), se pueden definir las acciones que deben llevarse a cabo:
- No hacer nada.
- No hacer nada pero generar logs de los eventos.
- Apagar las máquinas virtuales e intentar reiniciarlas.
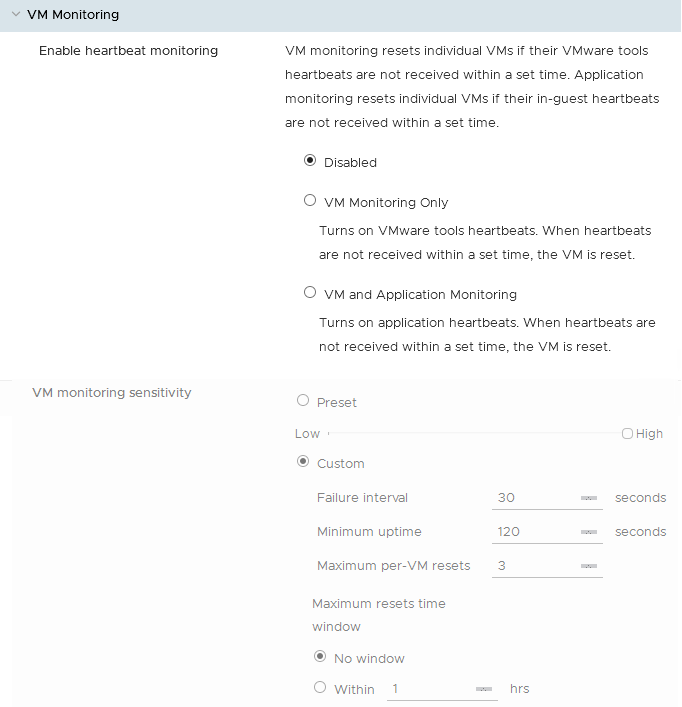
Supervisión de las MV
La supervisión de las máquinas virtuales está disponible después de instalar las VMware tools. En caso de no haber respuesta a través de las tools(latidos), la máquina virtual se reiniciará de forma automática. Se puede realizar una configuración avanzada con respecto a esta funcionalidad (por ejemplo, con intervalos de reinicio).
Control de admisión
vSphere HA utiliza el control de admisión para garantizar que se reserven recursos suficientes para la recuperación de máquinas virtuales cuando se produce un fallo en el host.
El control de admisión impone restricciones sobre el uso de recursos. No se permite ninguna acción que pueda infringir estas restricciones. Algunos ejemplos de acciones que pueden no estar permitidas son:
- Encendido de una máquina virtual
- Migración de una máquina virtual
- Aumento de la reserva de CPU o de memoria de una máquina virtual
El control de admisión de vSphere HA se basa en la cantidad de errores de host que el clúster puede tolerar sin perder la capacidad de conmutación por error. La capacidad de conmutación por error del host puede definirse de tres formas:
Almacén de datos de latidos
Cuando el host principal de un cluster HA no puede comunicarse con un host subordinado en la red de gestión, el host principal utiliza el latido de almacén de datos para determinar si el host subordinado tiene fallos, si se encuentra en una partición de red o si está aislado de la red.
Opciones avanzadas
Es posible realizar varios ajustes de configuración avanzada en el cluster.
Para ello, debe dirigirse a esta página.
Regla HA
En la sección configuración, en la pestaña Reglas MV/Host, se puede crear una regla del tipo «Máquinas virtuales a máquinas virtuales».
Esta añadirá una condición de reinicio para garantizar que las máquinas virtuales de un primer grupo se enciendan antes de encender las de un segundo grupo.
Esta regla puede añadirse como complemento de las prioridades de reinicio configurables en la pestaña Sustituciones de MV.
Más información
Interactúe con nuestra comunidad de usuarios en https://community.ovh.com/en/.

