Supervising your HAProxy deployment with Logs Data Platform
311 visualizaciones
Objective
HAProxy is the de-facto standard load balancer for your TCP and HTTP based applications. This French software provides high availability, load balancing, and proxying with high performance, unprecedented reliability and a very fair price (it's completely free and open-source). It is used by the world's most visited web sites and is also heavily used internally at OVHcloud and in some of our products.
HAProxy has a lot of features and because it is located between your infrastructure and your clients, it can give you a lot of information about either of them. Logs Data Platform helps you to exploit this data and can answer a lot of your questions:
- What is the most visited webpage?
- What is the slowest API Call?
- When is your traffic at its peak?
- How much data is going out from your infrastructure?
- Where are your clients from?
- How long do your clients stay on your websites?
- Are all of your back-end servers healthy?
This guide will show you two ways to forward your HAProxy logs to the Logs Data Platform. Both ways will use rsyslog to send logs. The first configuration will leverage Logstash parsing capabilities, and the second will use the custom log format feature of HAProxy to send logs using the LTSV Format.
Requirements
For this tutorial, you should have read the following ones to fully understand what's next:
- Starting with Logs Data Platform.
- Field Naming conventions of Logs Data Platform.
- How to setup a Logstash input?
Instructions
HAProxy:
HAProxy is a powerful software with many configuration options available. Fortunately the configuration documentation is very complete and covers everything you need to know for this tutorial. This tutorial is not a HAProxy tutorial so it will not cover how to install, configure and deploy HAProxy but you will find material on the matter on the official website. Depending on your backend you have the choice between several formats for your logs:
- Default format: Despite giving some information about the client and the destination, this format is not really verbose and cannot really be used for any deep analysis.
- Tcp Log format: This format gives you much more information for troubleshooting your tcp connections and is the one you should use when you have no idea what type of application is started behind your backend.
- Http Log Format: As the name suggests, this format is the most suitable option to analyze the protocol. Of course it only makes sense when your HAProxy is acting as an HTTP proxy. It gives even more information than the tcp log like the HTTP status code for example.
- Custom Log Format: This one allows you to fully customize the log format by using flags. You fully control what information you log.
Here is an example of a log line with the HTTP log format :
Every block of this line (including the dashes characters) gives one piece of information about the terminated connection. On this single line you have information about the process, its pid, the client ip, the client port, the date of the opening of the connection, the frontend, backend and server names, timers in milliseconds waiting for the client, process buffers, and server, the status code, the number of bytes read, the cookies information, the termination state, the number of concurrent connection respectively on the process, the frontend, the backend and the servers, the number of retries, the backend queue number and finally the request itself. You can visit the chapter 8 on HAProxy Documentation to have a detailed description on all these formats and the available fields.
To activate the logging on HAProxy you must set a global log option on the /etc/haproxy/haproxy.cfg.
This option tells HAProxy to route logs to the /dev/log socket with different syslog facilities: local0 facility by default and local1 for notice level messages. To specify the logging type for a backend, a frontend or a listen directive you use a simple option:
We can send logs to Logs Data Platform by using several softwares. One of them is Rsyslog, the other one is Filebeat. You're free to use whichever method looks more familiar to you.
Rsyslog:
Rsyslog is a fast log processor fully compatible with the syslog protocol. It has evolved into a generic collector able to accept entries from a lot of different inputs, transform them and finally send them to various destinations. Installation and configuration documentation can be found at the official website. Head to http://www.rsyslog.com/doc/v8-stable/ for detailed information.
To send HAProxy logs with RSyslog, we will use several methods: a dedicated Logstash collector and the plain LTSV format. The first method is the least intrusive and can be used when you need Logstash processing of your logs (for example to anonymize some logs under some conditions). The second method should be preferred when you have a high traffic website (at least 1000 requests by second.).
For both methods you will need our SSL certificate to enable TLS communication. Some Debian Linux distributions need you to install the package rsyslog-gnutls to enable SSL.
Exploit a dedicated Logstash Data-Gathering tool
Once you have activated the tcp or http logs of your HAProxy instance, you must then send them and transform them. For this part of the tutorial you will need your own dedicated Logstash collector. Logstash is one of the most powerful tool to transform logs. Create a Logstash data-gathering tool as described in the Logstash tutorial, and configure the port 1514 (or the port of your choice) as the exposed port.
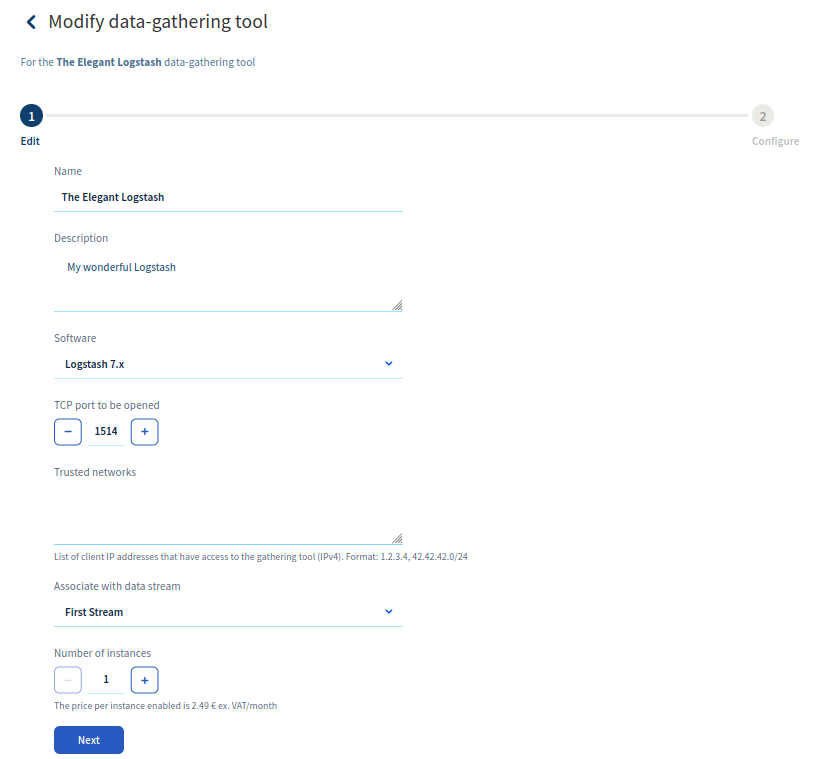
Logstash collector configuration
As you may guess we have to configure the Logstash collector with some clever Grok filters to make the collector be aware of our field naming convention. The collector will accept logs in a generic TCP input and use grok filters to extract the information. Thanks to the wizard feature, you won't even need to copy and paste the following configuration snippets, but they are still given for reference purpose.
Here is the Logstash input configuration:
This configuration should be familiar, we set the port, the ssl parameter and the ssl configuration with our provided certificates. Let's continue with the filter part. The custom grok used will be described hereafter:
The filter is divided in 3+1 parts. The first 3 parts are grok filters that try to parse the different format. If failing (with a _grokparsefailure tag), it tries another log format. HTTP, TCP and the error log format are the one tried. The last part is a date filter. This filter is used to translate the dates to the correct ISO 8601 format we use for date parsing. This filter is only executed when one of the previous filter was successful.
Every grok pattern has a dedicated part of the log line to parse.
- OVHHAPROXYTIME: This parses the time to extract the hour, minutes and seconds of the connection.
- OVHHAPROXYDATE: This parses the date to extract the day of month, the month, the year and the milliseconds by leveraging the previous pattern.
- OVHSYSLOGHEAD: This can parse an eventual syslog header. We won't use it but it can be useful with some flavors of syslog.
- OVHHAPROXYHEAD: This parses the rsyslog header and the time of reception of the log.
- OVHHAPROXYHTTPBASE: This is the main grok pattern extracting all the information included in an HTTP log line. It uses the field naming convention.
- OVHHAPROXYHTTP: By using a previous header pattern combined with the OVHHAPROXYHTTPBASE, this pattern is the one used in the grok filter.
- OVHHAPROXYTCP: This pattern is the main pattern used to parse TCP logs. It will also use the field naming convention.
- OVHHAPROXYERROR: This pattern will parse any connection error log.
You can then click on Test the configuration to validate it.
Rsyslog basic configuration
Rsyslog will be configured to complete 2 actions:
- Send logs to Logs Data Platform
- Keep logs in a dedicated file
For the first action you will need the collector certificate and its hostname, you will find them both in the menu of your collector
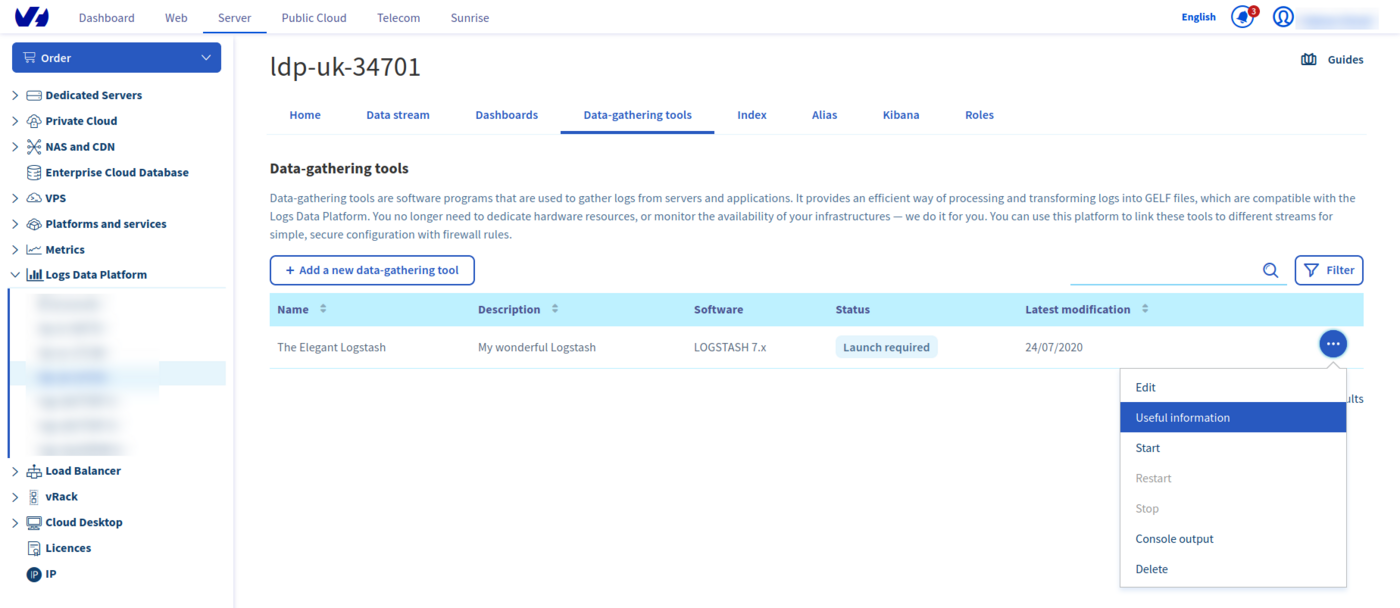
Copy the certificate in a file logstash.pem and copy the hostname and your port. Depending of your flavor of rsylog and HAProxy, your configuration file may be already present at a particular location. If you do not have any HAProxy related file in the directory /etc/rsyslog.d/, create a new file in this directory. If the directory does not exist , simply edit the /etc/rsyslog.conf file. Don't hesitate to review the rsyslog documentation to have more information. On Debian flavors for example, if you used the rsyslog and HAProxy packages you may have a file located in /etc/rsyslog.d/46-haproxy.conf. In that case, you should prefer editing this file.
The important settings here are the logstash.pem path location, activation of gtls and the collector hostname configuration. Note that this configuration keeps the logs in a dedicated file /var/log/haproxy.log.
Use the high performance LTSV format
You can use the high performance LTSV format with HAProxy by using a custom format. This option is best suited for high traffic websites and is highly customisable. You can remove fields that you don't need in your logs or add some optional ones (like SSL ciphers and version used in the connection, client port, request counter...). To configure it you will need to specify your format in the HAProxy configuration file and then configure your rsyslog configuration to enclose the log line into a compatible LTSV log line. Moreover you can spawn your own high-performance collector with Flowgger on Logs Data Platform to have even more security and performance.
HAProxy log format configuration
The flags used to define your log format are described in the HAProxy documentation (section 8.2.4 in the version 1.8 of HAProxy). Here is an example of a log format that is fully compatible with our field naming convention. In place of your previous log option, use the following entry:
This format not only defines which values are logged but also the final name of the fields that will be used in Logs Data Platform.
Rsyslog template configuration
Rsyslog configuration will be enhanced by using an LTSV template instead of the default configuration. If you have configured your own Flowgger collector on Logs Data Platform, use its certificate and hostname. If you want to use the global LTSV input of your cluster, head to the Home page to copy your cluster certificate and get your LTSV endpoint port. You should choose the LTSV line port for this use case. One of the downside of using the global input is that you will have to provide the token of your stream in a X-OVH-TOKEN field. Navigate to the Stream page on the OVHcloud Manager to retrieve your token.
Here is the rsyslog configuration:
<TAB> are placeholders! You should replace every by proper tabulation characters.
In this configuration, we added some $Action directives to have a more robust configuration and never lose messages when there is a network issue for example. As we mentioned before, you should replace the $DefaultNetstreamDriverCAFile path to your endpoint certificate path. This setup uses two templates that are used in two different cases. The first one is when the incoming message is an LTSV one. We detect it by looking for tabulations characters in the message. If there is no tabulation, we use the second template: it means it is an unexpected message and to not lose it, we enclose it in a dedicated message: field. These templates add some information like the token. You should put your own stream token in both template and you can also add any custom field.
Filebeat
Filebeat and its HAProxy module allow you to bypass the log formatting step entirely. You will still need RSyslog or any equivalent software to retrieve the logs from HAProxy. On Debian/Ubuntu, the HAProxy package will also setup the rsyslog configuration file at the following path /etc/rsyslog.d/49-haproxy.conf. You may have to restart Rsyslog to see logs appearing in the default path /var/log/haproxy.log.
After you have downloaded filebeat, you need to enable the HAProxy module by running the following command:
Edit your filebeat.yml configuration file to include the following snippet to enable log file reading in the module and to configure filebeat with our special OpenSearch input.
In this configuration you have to replace the token by your X-OVH-TOKEN value of your destination stream. Note that you also got to indicate the username and password or your token. Don't change the destination index ldp-logs. Start your filebeat and head to Logs Data Platform to start analyzing your logs.
Dashboard and alerts
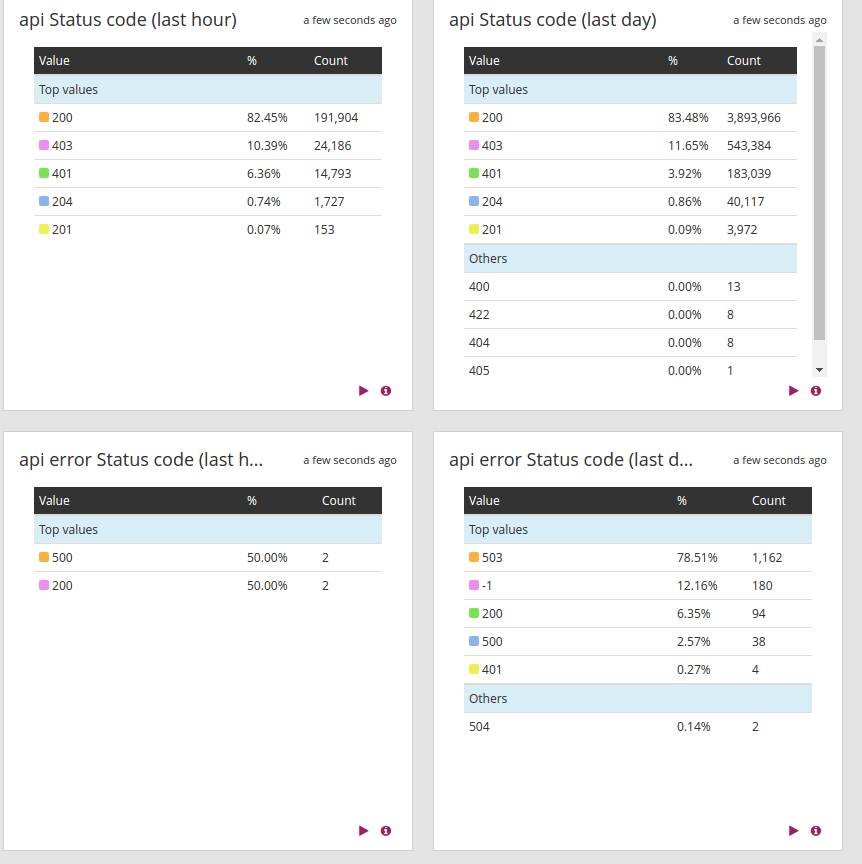
Here is an example of a dashboard that you can craft from the HAProxy logs. HAProxy logs give you a lot of information about your application and infrastructure. It's up to you to exploit them in whichever way suits you best. You can also configure some alerts to warn you when a backend is down or is not responding properly.


Go further
- Getting Started: Quick Start
- Documentation: Guides
- Community hub: https://community.ovh.com
- Create an account: Try it!

