AI Endpoints - Integration with Hugging Face Inference Providers
14 visualizaciones
AI Endpoints is covered by the OVHcloud AI Endpoints conditions and the OVHcloud Public Cloud special conditions.
New integration available: We're excited to announce a new integration for AI Endpoints with Hugging Face Inference Providers. This integration offers streamlined, unified access to world-class inference partners, and continues our commitment to integrating AI Endpoints into as many open-source tools as possible to simplify its usage.
Objective
OVHcloud AI Endpoints allows developers to easily add AI features to their day-to-day developments.
In this guide, we will show how to use Hugging Face Inference Providers to access OVHcloud AI Endpoints models through Hugging Face's unified interface.
With Hugging Face's Inference Providers and OVHcloud's scalable AI infrastructure, you can access a wide range of AI models using familiar APIs, whether you're working in Python or JavaScript/TypeScript.

Definition
- Hugging Face Inference Providers: A platform that offers streamlined, unified access to hundreds of machine learning models powered by world-class inference partners. It provides a single interface to access models from multiple providers, including OVHcloud AI Endpoints, with flexible provider selection strategies.
- AI Endpoints: A serverless platform by OVHcloud providing easy access to a variety of world-renowned AI models including Mistral, LLaMA, and more. This platform is designed to be simple, secure, and intuitive with data privacy as a top priority.
Why is this integration important?
This new integration offers you several advantages:
- Unified access: Access hundreds of models through a single, familiar interface.
- Flexibility: Choose between automatic, performance-based, or provider-specific selection.
- Multi-language support: Use Python or JavaScript/TypeScript with the same models.
- OpenAI compatibility: Use the OpenAI SDK for familiar syntax.
- Cost control: Choose between Hugging Face billing or Bring Your Own Key (BYOK) with OVHcloud AI Endpoints.
Requirements
Before getting started, make sure you have:
- An OVHcloud account with access to AI Endpoints.
- A Hugging Face account (sign up at huggingface.co).
- A Hugging Face access token with "Make calls to Inference Providers" permissions (create at huggingface.co/settings/tokens).
- Python 3.8 or higher (for Python usage) or Node.js (for JavaScript/TypeScript usage).
- Optionally, an OVHcloud AI Endpoints API key for Bring Your Own Key (BYOK) billing.
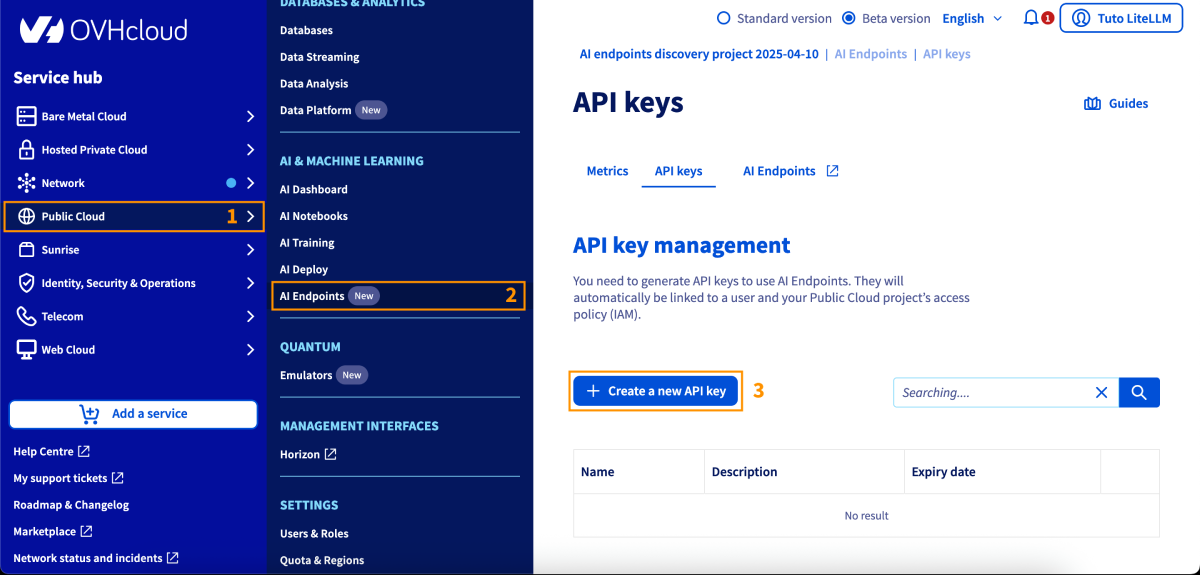
Instructions
Installation
Python
Install the required packages via pip:
Then, you can authenticate yourself with:
or add your key to the environment variable export HF_TOKEN=....
You are now ready to get started.
JavaScript / TypeScript
Install the required packages via npm:
And add your key to the environment variable export HF_TOKEN=....
You can now get started.
Basic configuration
Bring Your Own Key (BYOK)
You can also use your OVHcloud AI Endpoints API key directly for billing through OVHcloud instead of Hugging Face. To enable this:
- Go to Hugging Face Inference Providers settings.
- Add your OVHcloud AI Endpoints API key.
- Usage will be billed directly to your OVHcloud PCI project.
Basic usage
Python - using OpenAI SDK
Here's a simple usage example using the OpenAI SDK:
Python - using Hugging Face Hub client
Alternatively, use the native Hugging Face Hub client:
JavaScript - using Hugging Face Inference client
Here's a simple usage example in JavaScript:
JavaScript - using OpenAI SDK
You can also use the OpenAI SDK in JavaScript:
Advanced features
Provider selection strategies
Hugging Face offers flexible provider selection strategies to optimize for your needs:
Automatic selection (default)
Uses the first available provider based on your preference order:
openai/gpt-oss-120b
Specific provider
Force the OVHcloud provider:
openai/gpt-oss-120b:ovhcloud
Performance-based selection
Select the fastest provider (highest throughput):
openai/gpt-oss-120b:fastest
Select the cheapest provider (lowest cost per token):
openai/gpt-oss-120b:cheapest
Setting provider preferences
Configure your preferred provider order at huggingface.co/settings/inference-providers.
Available models
OVHcloud AI Endpoints offers a wide range of models accessible via Hugging Face Inference Providers. For the complete and up-to-date list, visit our model catalog or browse OVHcloud models on Hugging Face.
Pricing and billing
Hugging Face Inference Providers uses a pay-as-you-go model with flexible billing options:
- Hugging Face billing: Usage is billed directly to your Hugging Face account.
- No setup costs: No infrastructure or commitment required.
- Cost control: Monitor usage in your Hugging Face settings.
- Bring Your Own Key (BYOK): Use your OVHcloud AI Endpoints API key to be billed directly by OVHcloud instead of Hugging Face. Configure this in Hugging Face Inference Providers settings.
Conclusion
In this article, we explored how to integrate OVHcloud AI Endpoints with Hugging Face Inference Providers to seamlessly access a wide range of AI models through a unified interface. Thanks to Hugging Face's Inference Providers, you can use familiar APIs in Python or JavaScript/TypeScript, with flexible provider selection and billing options, while OVHcloud AI Endpoints ensures secure, scalable, and production-ready AI infrastructure.
Go further
You can find more information about Hugging Face Inference Providers on their official documentation. You can also browse the AI Endpoints catalog to explore the models that are available.
For detailed information about OVHcloud on Hugging Face Inference Providers, visit the OVHcloud provider documentation.
Browse OVHcloud models on Hugging Face to discover all available models.
For more information about the Hugging Face Hub Python library, visit the official documentation.
Browse the full AI Endpoints documentation to further understand the main concepts and get started.
If you need training or technical assistance to implement our solutions, contact your sales representative or click on this link to get a quote and ask our Professional Services experts for a custom analysis of your project.
Feedback
Please feel free to send us your questions, feedback, and suggestions regarding AI Endpoints and its features:
- In the #ai-endpoints channel of the OVHcloud Discord server, where you can engage with the community and OVHcloud team members.
- Join the Hugging Face community on Discord for questions about Hugging Face Inference Providers.

