Sustituir un disco en caliente en un servidor con RAID por software
1761 visualizaciones
Esta traducción ha sido generada de forma automática por nuestro partner SYSTRAN. En algunos casos puede contener términos imprecisos, como en las etiquetas de los botones o los detalles técnicos. En caso de duda, le recomendamos que consulte la versión inglesa o francesa de la guía. Si quiere ayudarnos a mejorar esta traducción, por favor, utilice el botón «Contribuir» de esta página.
Objetivo
En los servidores Alta Gama compatibles, es posible sustituir un disco dañado en caliente.
Esta guía explica qué pasos debe seguir para sustituir en caliente un disco de un servidor con RAID por software.
Requisitos
- Tener contratado un servidor mHG, HG o BHG.
- Tener RAID por software (con tarjeta LSI).
- Tener acceso por SSH (Linux) o RDP (Windows).
- Haber instalado la utilidad sas2ircu (disponible en la web de Broadcom).
Procedimiento
En Linux
1. Identificar el disco dañado
En esta guía partiremos del supuesto de que el cliente ha recibido una alerta indicándole que el disco /dev/sdb falla e invitándole a proceder a su sustitución en caliente. No olvide adaptar los comandos indicados en esta guía a su caso particular.
En primer lugar, compruebe el serial number (número de serie) del disco dañado.
En la respuesta al comando anterior puede comprobar lo siguiente:
- el disco sdb está fuera de servicio debido a que presenta errores no corregidos (uncorrected errors);
- su serial number se corresponde con el de la alerta recibida (enviada desde el datacenter o a través de cualquier otra herramienta de monitorización).
Para obtener solamente el serial number, utilice el siguiente comando:
2. Conocer la posición del disco
A continuación, identifique el slot y el enclosure del disco dañado. Para ello, utilice la herramienta sas2ircu, previamente instalada en el servidor.
En primer lugar, compruebe que los discos están conectados a través de una tarjeta LSI.
Si ese es el caso, identifique el ID de dicha tarjeta LSI.
El index (índice) corresponde al ID. En el ejemplo, el index, y por tanto, el ID de la tarjeta es 0.
Con esta información podrá obtener el slot y el enclosure del disco dañado a través de su serial number.
Este comando permite consultar la información del disco, cuyo serial number es el K4GW439B.
En nuestro ejemplo, hemos obtenido el enclosure (que aquí corresponde a 1) y el slot (en este caso, 3).
3. Encender el led del disco
Una vez que disponga de los datos que se indican en los pasos anteriores, encienda el led del disco que deba ser sustituido con el comando ./sas2ircu 0 locate Enc:Slot on (no olvide sustituir «Enc» y «Slot» por el enclosure y el slot previamente obtenidos):
Puede desactivar el parpadeo del disco sustituyendo on por off en el comando anterior.
4. Sacar el disco dañado del RAID
Si todavía no lo está, ponga el disco dañado en faulty. A continuación, compruebe el estado del RAID.
En nuestro ejemplo, el disco dañado forma parte de «md1» y «md2» («sdb1» y «sdb2»). Así pues, pondremos en faulty «sdb1» y «sdb2» de «md1» y «md2» respectivamente.
Una vez completada esta operación, vuelva a comprobar el estado del RAID.
Como podemos ver arriba, «sdb1» y «sdb2» ya están en faulty (F), así que ya puede proceder a sacar el disco del RAID.
Por último, compruebe que el disco ya no esté presente.
El disco dañado ya puede ser sustituido por un técnico del datacenter. Una vez realizada la intervención, solo tendrá que resincronizar el RAID. Para ello, consulte la guía RAID por software.
En Windows
1. Identificar el disco dañado
En esta guía partiremos del supuesto de que el cliente ha recibido una alerta indicándole que el disco /dev/sdb falla e invitándole a proceder a su sustitución en caliente. No olvide adaptar los comandos indicados en esta guía a su caso particular.
Es importante abrir el terminal como administrador para evitar errores.
En primer lugar, compruebe el serial number (número de serie) del disco dañado. En la siguiente captura, el almacenamiento en realidad no está fuera de servicio.
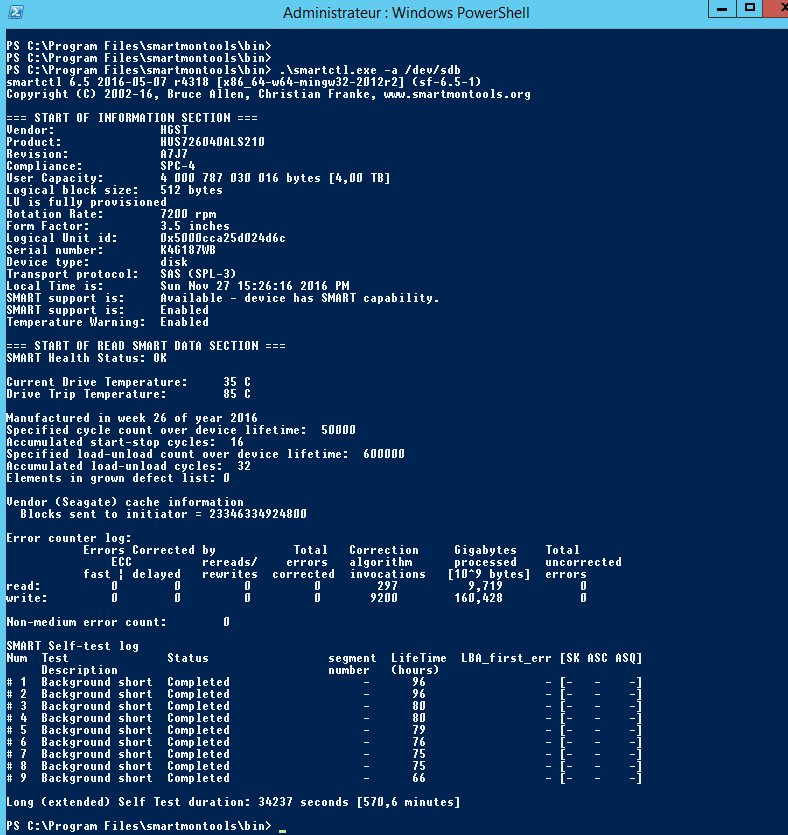
En la respuesta al comando anterior puede comprobar lo siguiente:
- el disco sdb está fuera de servicio debido a que presenta errores no corregidos (uncorrected errors);
- su serial number se corresponde con el de la alerta recibida (enviada desde el datacenter o a través de cualquier otra herramienta de monitorización).
2. Conocer la posición del disco
A continuación, identifique el slot y el enclosure del disco dañado. Para ello, utilice la herramienta sas2ircu, previamente instalada en el servidor.
Identifique el ID de la tarjeta LSI.
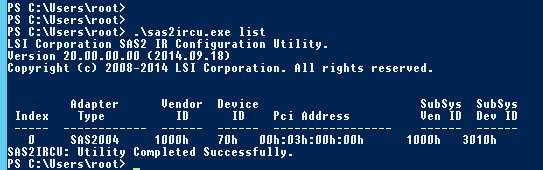
En el ejemplo, el index (índice) y, por tanto, el ID de la tarjeta es 0.
Con esta información podrá obtener el slot y el enclosure del disco dañado a través de su serial number.
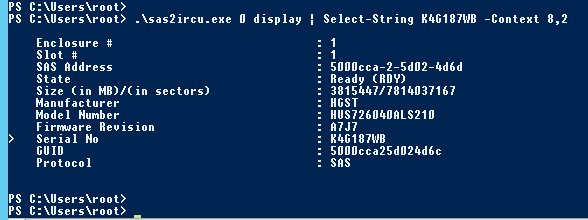
El comando anterior permite consultar la información del disco, cuyo serial number es el K4G187WB.
En nuestro ejemplo, hemos obtenido el enclosure (que aquí corresponde a 1) y el slot (en este caso, 1).
3. Encender el led del disco
Una vez que disponga de los datos que se indican en los pasos anteriores, encienda el led del disco que deba ser sustituido con el comando .\sas2ircu 0 locate Enc:Slot on (no olvide sustituir «Enc» y «Slot» por el enclosure y el slot previamente obtenidos):
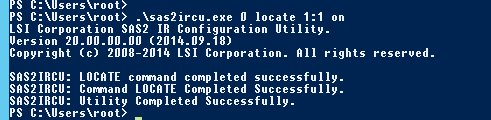
Puede desactivar el parpadeo del disco sustituyendo on por off en el comando anterior.
4. Sacar el disco dañado del RAID
Esta operación puede realizarse desde la utilidad Administración de discos del servidor Windows.
A continuación, el disco dañado ya podrá ser sustituido por un técnico del datacenter. Una vez realizada la intervención, solo tendrá que resincronizar el RAID. Para ello, consulte la guía RAID por software.
Más información
Interactúe con nuestra comunidad de usuarios en https://community.ovh.com/en/.

