3-AZ resilience: Mechanisms and reference architectures
816 Views
Objective
This guide aims at educating and supporting customers on the principles of resilience in 3-AZ and the associated reference architectures. It details how OVHcloud services are designed to operate in a multi-AZ environment, deployment best practices and mechanisms for ensuring high availability. A table of 3-AZ service specifications is provided, along with examples of 2-AZ architectures to help users structure their infrastructures in a resilient way.
Deployment and resilience of 3-AZ services
In a cloud environment, service availability and resilience are essential to guarantee business continuity, even in the event of an Availability Zone (AZ) failure. This document presents the different cloud offerings and their resilience mechanisms when deployed over three availability zones (3-AZ).
The table below lists the services offered, their scope (zonal or regional), and the best configuration practices for ensuring optimum resilience. Finally, it details the expected behavior in the event of an AZ failure, to help customers anticipate risks and set up appropriate architectures.
| Service | Zonal/Local | Regional | Architecture/Configuration Best Practices | In case of AZ failure |
|---|---|---|---|---|
| Instances | As instances are zonal services, they are only deployed in a single availability zone. To ensure resilience, customers must manually distribute their instances over several availability zones. Depending on your application, use case and services, a regional load balancer and a multi attached classic block volume may be the recommended architecture to leverage on resilience. For example, an active/passive clustered database distributed over two AZs can automatically switch from one instance to the other without a Load Balancer. | In the event of failure of one AZ, with resilience mechanisms, service continuity is ensured by your instances in the other AZs. | ||
| Private Network | DHCP/DNS agents operate in two AZs. If one AZ fails, they will be automatically reactivated in the AZ where they are not already running. | |||
| Public Cloud Load Balancer ( Octavia ) | The regional Load Balancer consists of an active Load Balancer and a passive Load Balancer, each deployed in a separate AZ. | The service will remain available without interruption. In the event of failure of an AZ containing a Load Balancer node, the latter will automatically be moved to the last AZ. | ||
| Gateway | The regional gateway consists of an active and a passive gateway, each deployed in a separate AZ. If an AZ containing a Gateway node fails, it will not be recreated in another AZ. | The service will remain available without interruption. | ||
| Floating IP | The customer can attach a multi-AZ Floating IP to any instance or Load Balancer in any AZ. | The service will remain available without interruption. | ||
| Object Storage ( Standard class ) | Object Storage is a regional service offering advanced data protection options, including integrated off-site replication via the Control Panel and S3-compatible asynchronous replication via the API for custom configuration. | No impact on Object Storage service or data. Data remains available for read and write operations, even in the event of an AZ failure. This configuration is ideal for high-availability, fault-tolerant applications. Once the AZ is restored, chunks are moved to the affected AZ. Learn more here. | ||
| Block storage High Speed | HighSpeed is a zonal service with triple replication within a single AZ. To ensure resilience, customers must manually deploy HighSpeed Block Storage on several AZs to ensure service continuity. The use of volume backups (local or distant) can also be interesting in some use cases to restore local block storage. | In the event of a major outage, as the service is zonal, customers could lose their data and will have to recreate their Block volume (from backups for example) when the AZ is restored. | ||
| Block storage Classic Multi-Zone | Block Storage Classic is a regional service using distributed erasure coding across several AZs. Off-site replication is recommended to protect against regional failure. | Block Storage data remains available without impact or downtime, provided the conditions of the multi-attached resilient architecture are met. For more information, please refer to our guide "Proper Usage and Limitations of Classic Multi-Attach Block Storage in 3AZ Regions". In the event of a major incident, chunks will be recreated as soon as the AZ is restored. | ||
| Managed Kubernetes Service | With the Managed Kubernetes on 3-AZ regions, the Control Plane is distributed over 3 AZs. The customer must deploy worker nodes on several AZs and use Multi-Zone/Regional Block Storage for persistent volumes. | In the event of an AZ failure, the Control Plane remains available and the customer's workload is rescheduled on the nodes on another available AZ. Note that workloads using persistent volumes of single-zone classes cannot be migrated to other AZs. When the AZ is restored, the Control Plane will become available again in the AZ and the unmigrated workload will resume. | ||
| DBaaS | Database nodes are distributed across several nodes in different AZs. Backup is useful in the event of regional failure or for a single-node database. | In the event of an AZ failure, databases and data will remain available. The Production and Advanced offerings include at least two nodes, ensuring no service interruption. Backups are automatically managed by our services and stored off-site. Learn more here. |
Reference architecture for Multi-AZ deployment
When deploying a zonal/local service (e.g. Compute instances or HighSpeed Block storage), this means that the service is compatible with the 3-AZ regions, but not automatically deployed in each single AZ of the region.
- For a 2-AZ architecture, you must manually create an instance in AZ-a and AZ-b.
- For a 3-AZ architecture, you need to create one instance in AZ-a, AZ-b and AZ-c.
This section presents reference architectures for multi-AZ deployment, illustrating different resilience scenarios in the face of AZ failure. Through detailed diagrams and technical explanations, we highlight best practices for designing robust infrastructures, guaranteeing service availability and optimizing disaster recovery.
The Public Cloud Control Plane, distributed accross all Availability Zones (AZ), plays a key role in the management and orchestration of cloud services. It handles load balancing, private network management, and resource and storage coordination.
During an incident on the AZ-a, the Control Plane remains available and operational, guaranteeing continuity of critical services. This enables the Floating IP and Load Balancer to dynamically adapt traffic to the instances still available, ensuring an uninterrupted user experience.
When AZ-a is restored, the Control Plane gradually reintegrates the resources and instances concerned into the overall infrastructure. For zonal services (e.g. instances, High Speed Block), if data has been lost, recovery depends on the implementation of a backup strategy. In the absence of backup, some recent data may remain irrecoverable, except for services such as Block Storage Classic Multi-Zone or Object Storage, which have built-in resilience mechanisms.
Multi-AZ resilience in the Public Cloud
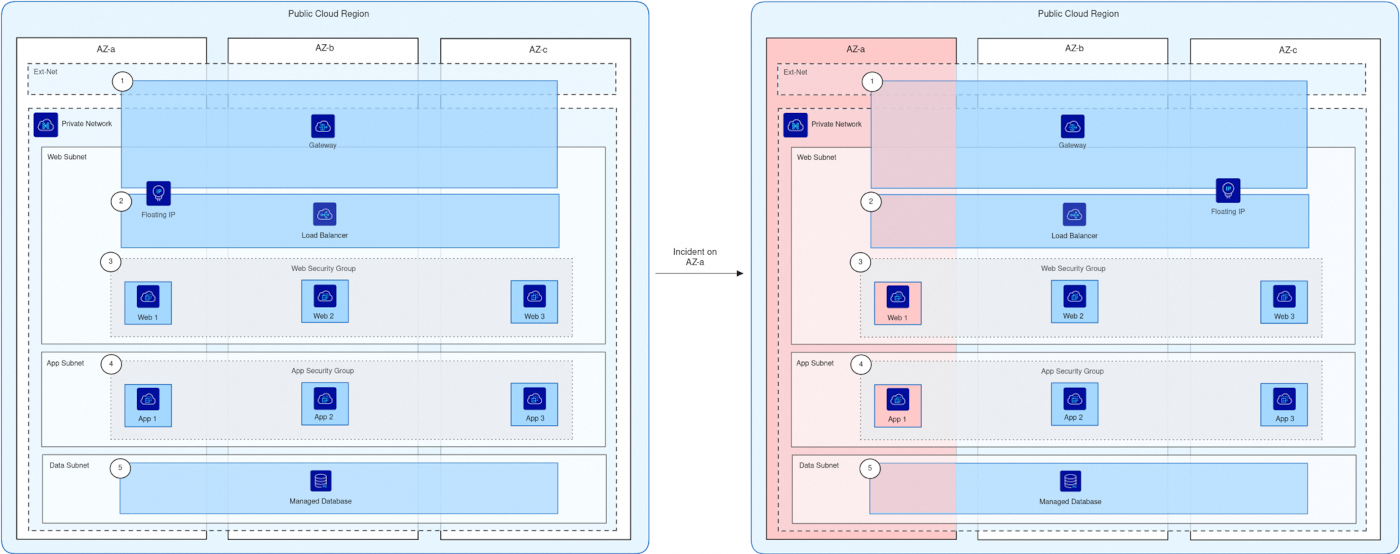
This diagram illustrates a three-tier application (web frontend, application backend, and database) deployed across three availability zones (AZ), relying on regional Public Cloud services (Load Balancer, managed database, Floating IP, and Gateway) to ensure high availability and resilience, even in case of an incident impacting one AZ.
- The Gateway exposes the Load Balancer publicly using a Floating IP.
- The Load Balancer distributes network traffic across the web instances.
- The web security group:
- Accepts only ingress traffic from the Load Balancer’s private IPs on the web port.
- Allows only egress traffic to the App security group on the App port.
- The App security group:
- Accepts only ingress traffic from the web security group on the App port.
- Allows only egress traffic to the managed database’s private IP and port.
- The managed database uses an ACL that only permits connections from the private IPs of the App instances.
Normal Operation (Left side):
- The application is deployed across three AZs (a, b, and c).
- All AZs are connected to the same Private Network.
- Web tier: 3 web instances are distributed across the AZs (Web 1 on AZ-a, Web 2 on AZ-b, Web 3 on AZ-c).
- App tier: 3 application instances are distributed across the AZs (App 1 on AZ-a, App 2 on AZ-b, App 3 on AZ-c).
- Data tier: A regional managed database is available across all AZs.
- A regional Load Balancer (with active/passive nodes managed by OVHcloud) distributes traffic between the web instances.
- Security groups restrict traffic between tiers:
- Web security group allows only connections from the Load Balancer and towards the App tier.
- App security group allows only connections from the web tier and towards the managed database.
- Connectivity is ensured by a Floating IP and a Gateway. Both services also rely on an OVHcloud-managed active/passive mechanism, so no additional deployment is required.
AZ-a Incident (Right side):
- AZ-a goes down, making Web 1 and App 1 unavailable.
- The Gateway in AZ-a becomes inaccessible, but the passive Gateway in another AZ automatically takes over (resilience managed by OVHcloud).
- The Load Balancer remains available thanks to its active/passive architecture managed by OVHcloud, and continues to distribute traffic across Web 2 and Web 3.
- The Floating IP remains available thanks to its active/passive mechanism, and continues routing requests to healthy instances.
- Application backend instances App 2 (AZ-b) and App 3 (AZ-c) continue to operate and handle requests.
- The regional managed database remains fully available across AZs.
- The application continues to serve users without interruption, though overall capacity is temporarily reduced.
Thanks to the regional services (Load Balancer, Gateway, Floating IP, and managed database), the application remains resilient and available throughout the incident. Once AZ-a is restored, Web 1 and App 1 automatically reintegrate into the system, and the application returns to full high-availability mode.
Recovery:
- Once AZ‑a is restored, its Web 1 and App 1 instances restart and synchronize with the rest of the application. They become active again and resume handling application traffic.
- Regional OVHcloud network services (Gateway, Load Balancer, Floating IP) in AZ‑a are reactivated, but do not return to their original active state. They remain passive, as the AZ where they were previously active continues to hold that role. OVHcloud manages the active/passive mechanism automatically to ensure resilience.
- The managed database continues to accept connections from AZ‑a and synchronizes normally.
- The Load Balancer gradually reintegrates Web 1 into the traffic distribution.
- The application regains full high availability (HA) across all three AZs. However, the active/passive state of the network services may differ from the initial configuration: AZ‑a is active for application instances but passive for network services, while the AZ that was originally active for network services remains active.
Deployment in 2-AZ with regional Block Storage
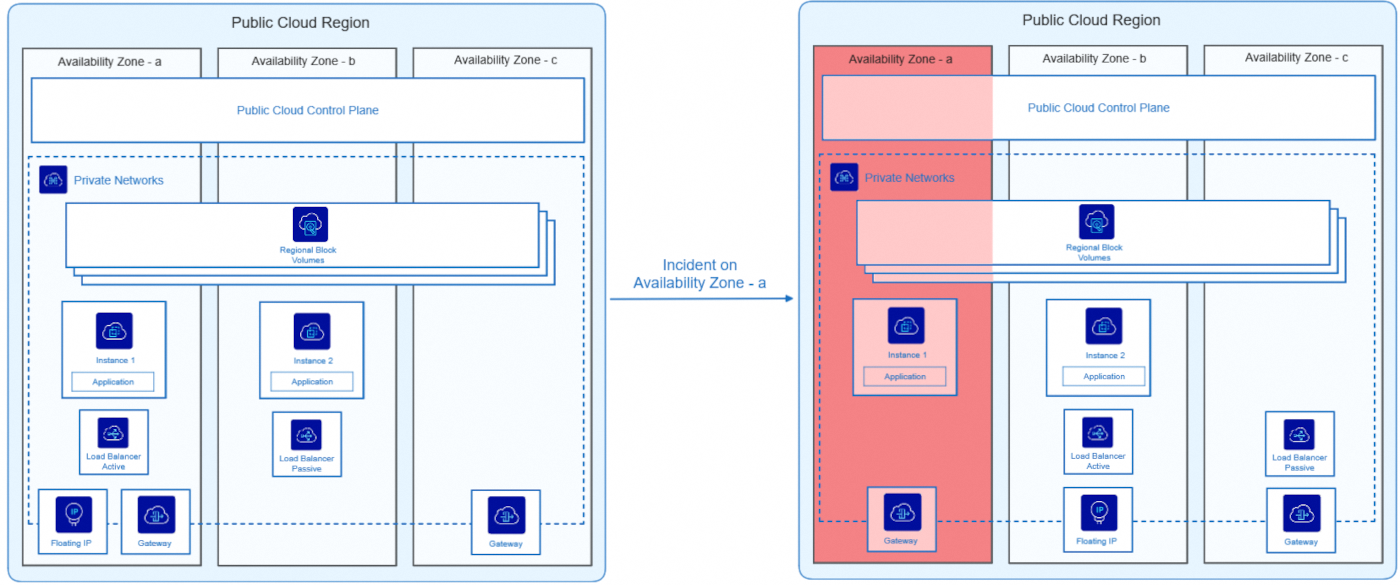
This diagram illustrates an application deployed across two availability zones (AZ), relying on a regional Block Storage service to ensure resilience:
Normal Operation (Left side):
- The app is spread over two AZs (a and b).
- The 2 AZs are in the same Private Network.
- Instance 1 runs on AZ-a and Instance 2 on AZ-b.
- An active Load Balancer distributes traffic on the AZ-a, with a passive Load Balancer waiting on the AZ-b.
- The Block Storage service is regional, shared between the AZs and simultaneously attached to both Instance 1 on AZ-a and Instance 2 on AZ-b. For more information, please refer to our guide "Proper Usage and Limitations of Classic Multi-Attach Block Storage in 3AZ Regions".
- Connectivity is provided by a Floating IP and a Gateway (including a second one available in case of failure).
AZ-a Incident (Right Side):
- The AZ-a goes down, making Instance 1 and the active Load Balancer unavailable.
- The AZ-a Gateway becomes inaccessible but a second one in another AZ takes over.
- The passive Load Balancer becomes active to ensure continuity of service.
- The Floating IP can dynamically be switched through Private Network to the AZ-b to allow continuous access to the application.
- Instance 2 (which is located in AZ-b) automatically takes over.
- The app remains available, but the app no longer works in High Availability (HA) mode.
Thanks to dynamic service transfer between availability zones, the application remained active throughout the incident, without interruption to users. Once AZ-a is restored, the application returns to its initial state and becomes high-available again.
2 AZ deployment with local Block Storage
This diagram illustrates a 2 AZ deployment architecture with a local Block Storage service.
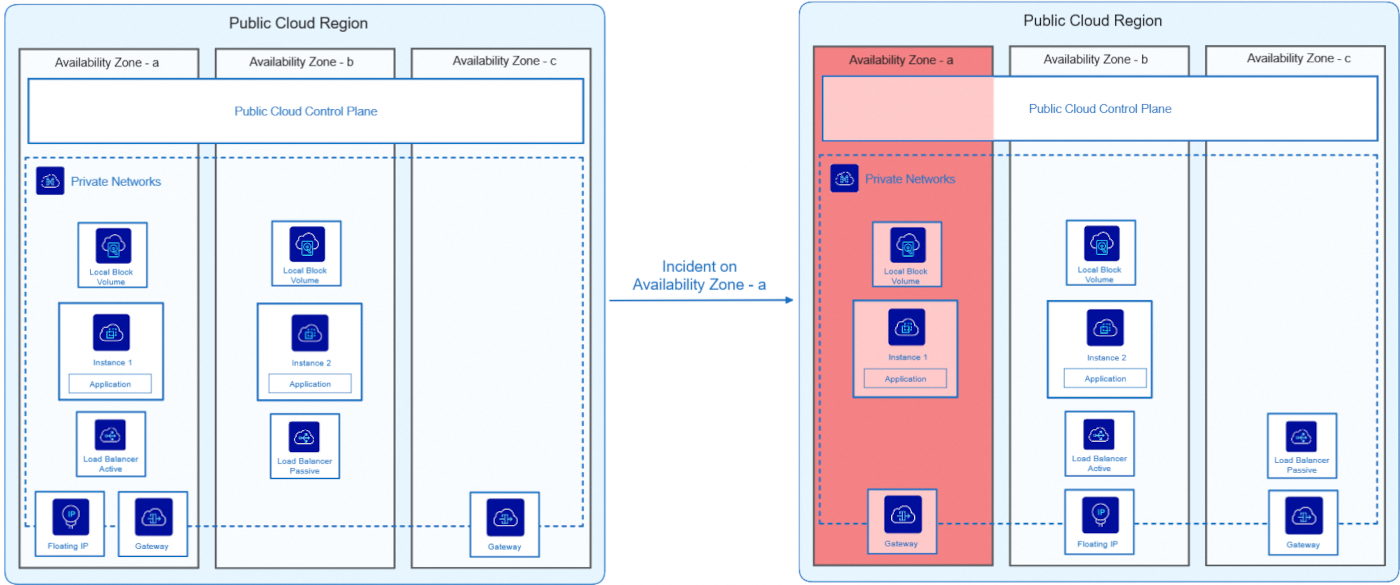
Normal Operation (Left Side):
- The app is spread over two AZs (a and b).
- The 2 AZs are in the same Private Network.
- Instance 1 runs on AZ-a, and Instance 2 on AZ-b.
- An active Load Balancer distributes traffic on the AZ-a, with a passive Load Balancer waiting on the AZ-b.
- The Block Storage service is local, meaning that each instance has its own volume attached to its AZ and not shared with the other AZ.
- Connectivity is provided by a Floating IP and a Gateway (including a second one available in case of failure).
Incident on AZ-a (Right Side):
- The AZ-a goes down, making Instance 1 and the active Load Balancer unavailable
- The AZ-a Gateway becomes inaccessible but a second one in another AZ takes over.
- The passive Load Balancer becomes active to ensure service continuity.
- The Floating IP can dynamically be switched through Private Network to the AZ-b to allow continuous access to the application.
- Instance 2 (which is located in AZ-b) automatically takes over.
- The app remains available, but the app no longer works in High Availability (HA) mode.
- Since the Block Storage service is local and not regional, data stored on the AZ-a instance can be temporarily or definitely (in case of major outage) lost until the zone is restored.
Thanks to dynamic service transfer between availability zones, the application remained active throughout the incident, without interruption to users. Once AZ-a is restored, the application returns to its initial state and becomes high-available again. A pre-scheduled backup can be useful to recover data and restore Block Storage volumes in case of major outage.
Go Further
If you need training or technical assistance to implement our solutions, contact your sales representative or click on this link to get a quote and ask our Professional Services experts for assisting you on your specific use case.
Join our community of users and visit our Discord channel.

