AI Deploy - Tutorial - How to load test your application with Locust
391 Views
AI Deploy is covered by OVHcloud Public Cloud Special Conditions.
Objective
The aim of this tutorial is to load test your deployed applications, by gradually querying your APIs with a load testing tool. Usually, your challenge is to forecast your compute needs, for example how many CPUs or GPUs will be required for 1000 API calls per hour and acceptable latency.
There are several applications to simulate the amount of users and requests that you may have to address.
In this tutorial, we will use one of them and interpret the results.
Requirements
- A Public Cloud project in your OVHcloud account.
- An app with an API running in AI Deploy on your Public Cloud project.
- A python environment, with enough CPU and RAM and internet access (a virtual machine is recommended).
OVHcloud Control Panel Access
- Direct link: Public Cloud Projects
- Navigation path:
Public Cloud> Select your project
Selecting the right load testing tool for your needs
Depending on your preferred programming language and time to spend on this topic, you can opt for different options.
First you can go for a SaaS load tester, such as Gatling.io or K6.io. Nothing to install, easy to start.
A second option is using open source load testing tools. Some tools are only command-line based, such as hey or Wrk2, others come with a web interface like Locust.
Selecting the right tool for the right test is mandatory. For the next parts, we will select and use Locust, allowing us to show visual graphs.
Instructions
Deploy an app with a REST API
Feel free to deploy any app and API that you would like to load test, as long as you can query it via REST queries.
For this tutorial, we will load test a spam classifier API from the AI Deploy app portfolio. This API takes sentences (emails) as input text, and outputs a spam probability score.
You can deploy this API easily from the OVHcloud control panel or OVHcloud CLI. A good strategy is to deploy with autoscaling, with minimum and maximum replicas. This way we will monitor the growth of used replicas.
Here is the CLI command used to deploy it, with autoscaling going from 1 to 5 replicas and a CPU threshold of 75%:
Verify that your API is up and running with cURL
To be able to connect to your AI Deploy app, you have to create a token bearer for your OVHcloud AI user.
Once deployed, let's test first our API with a simple cURL command. Here is the command to try in a terminal:
Here is the result given by our call:
A few explanations on the lines above:
- In the first line, we specify that we will use a POST method.
- We specify the url where the POST request will be executed. The
api_urlis the url of your API. It should be similar to:https://baac2c13-2e69-4d0f-ae6b-dg9eff9be513.app.gra.ai.cloud.ovh.net/. - We put the token to access our API, generated via the OVHcloud Control Panel or
ovhaiCLI. We specify it in the header of the request. If you want to know more about generation and use of tokens, you can follow this tutorial. - We specify that our body is in a JSON format.
- We put in our body the message we want to send to the spam classifier. In your case, the body could be different because it depends of the API. Our objective is that the spam classifier will send us the probability of each response. The last
| jqinstruction allows us to have a good display of the result in the terminal.
We now have the confirmation that our API is up and running, let's try to load test it.
We will simply simulate several curl commands. With the Locust tool, we can simulate several users and define a number of calls per minute to the API. This can be easily done with Locust's interface. But before using this interface, we need to launch Locust and configure the tool. This can be easily done with python.
Install locust.io
Locust is an open source Python package that you can install with one line of code. Follow their official documentation:
You can install it on your personal computer, but keep in mind that load testing tools will require four elements to not become the bottleneck in your load test:
- Enough compute (CPU).
- Enough memory (RAM).
- Low latency connectivity to your API.
- No "noisy neighbors", meaning no software installed that can compromise your results. Imagine your CPU power getting used by video rendering, it will bias your results.
For all these reasons, a Public Cloud instance is recommended, such as a medium-sized virtual machine. For this tutorial, we will use an OVHcloud B2-30 instance.
Configure Locust
To configure the software, you need to create a file named locustfile.py. In this file, you can put the path where you want to make your request, the headers of your request, the type of the request (POST, GET, etc) and the body if you want to add a body to the request.
A generic file will look like this:
For our API and our needs, the locust file will be slightly modified:
For your own needs, you will have to change the path, the headers and the body because these are parameters which change from one API to another.
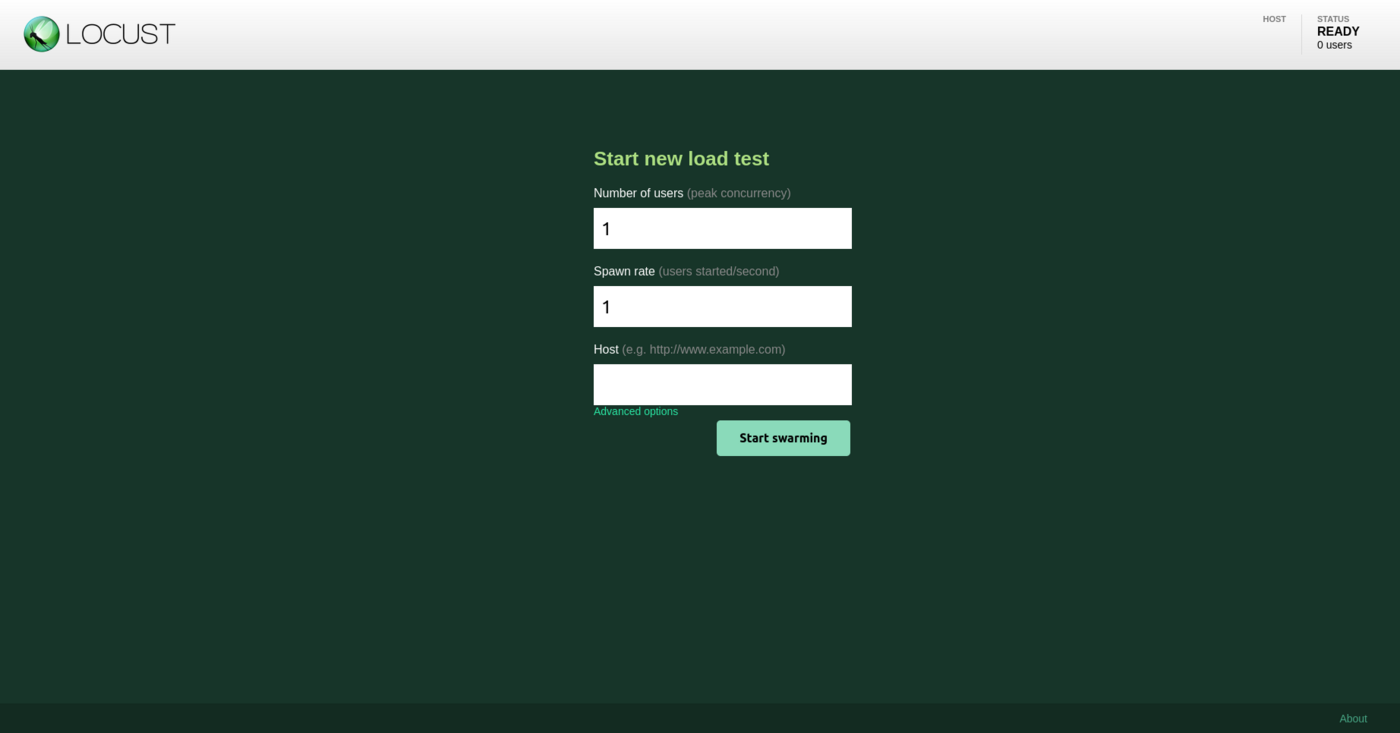
Once your locustfile.py is ready, open the Locust web interface on <http://your_IP:8089>.
The web interface should look as below:
Run your load tests
You now have your app running on OVHcloud, and Locust configured. Let's simulate some user calls.
From the web interface, fill in the amount of simultaneous users (API calls) and incremental step (spaw rate).
For this tutorial, we will add 480 users in total, and a spawn rate of 2 users added per second. We will simulate this for a duration of 4 minutes. We suppose that this case is for a rush on the API. Most of the times, we can assume that there aren't so many users on the platform.
Launch the test.
Interpret the results via Locust
At the end of the load test, you will see this quick summary:

If we want to get more details about our test, we can see the graphs provided by Locust in the charts tab. Here is what we can see:
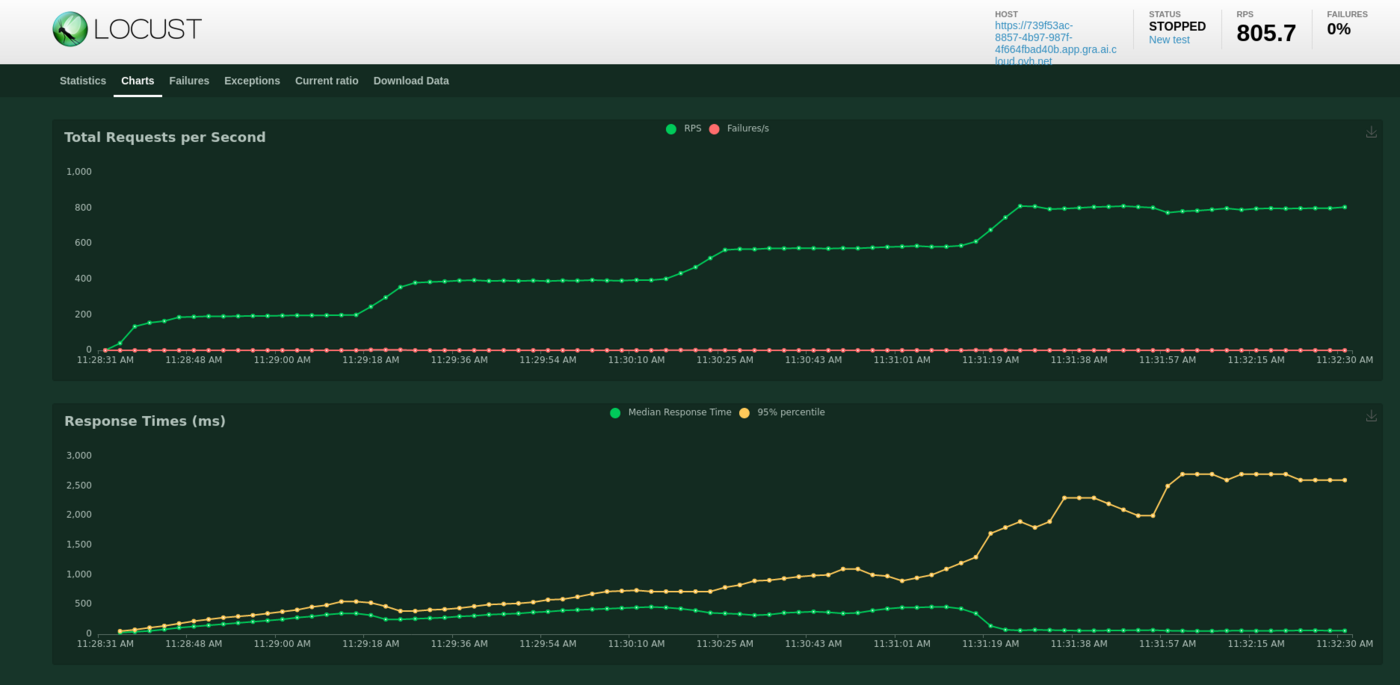
We deployed this API from 1 to 5 replicas, with 1 CPU for each of them, completed with auto-scaling. We can see that our API has been a bit overloaded. Indeed, with the graphics or with the quick summary, we can see some failures. These failures are due to server errors. We may suppose that we reached some hardware limits at some point, for example before scaling to a greater amount of replicas.
Also, we can see an increasing call latency over time. At the end, we can expect more than 3 seconds per call.
Result interpretation may depend of your needs and performance criterias. We can of course make a new test with more users to see the limits of our APIs, and put several tasks in the locustfile.py.
One thing can not be seen here: OVHcloud backend scaling. We deployed our app with autoscaling, from 1 replica minimum to 5 replicas maximum. Did we use them ? Were they useful and at maximum capacity?
Let's see the same results in details with the AI Deploy monitoring tool.
Interpret the results with the AI Deploy Monitoring
Go in the OVHcloud Control Panel and get the detail of your deployed application. Click on the Access Dashboards button.
This dashboard is provided for free in AI Deploy, for each deployed application. All of the deployed apps are combined in a simple Grafana Dashboard.
You can select the deployed app at the top of this Grafana dashboard, as shown below:
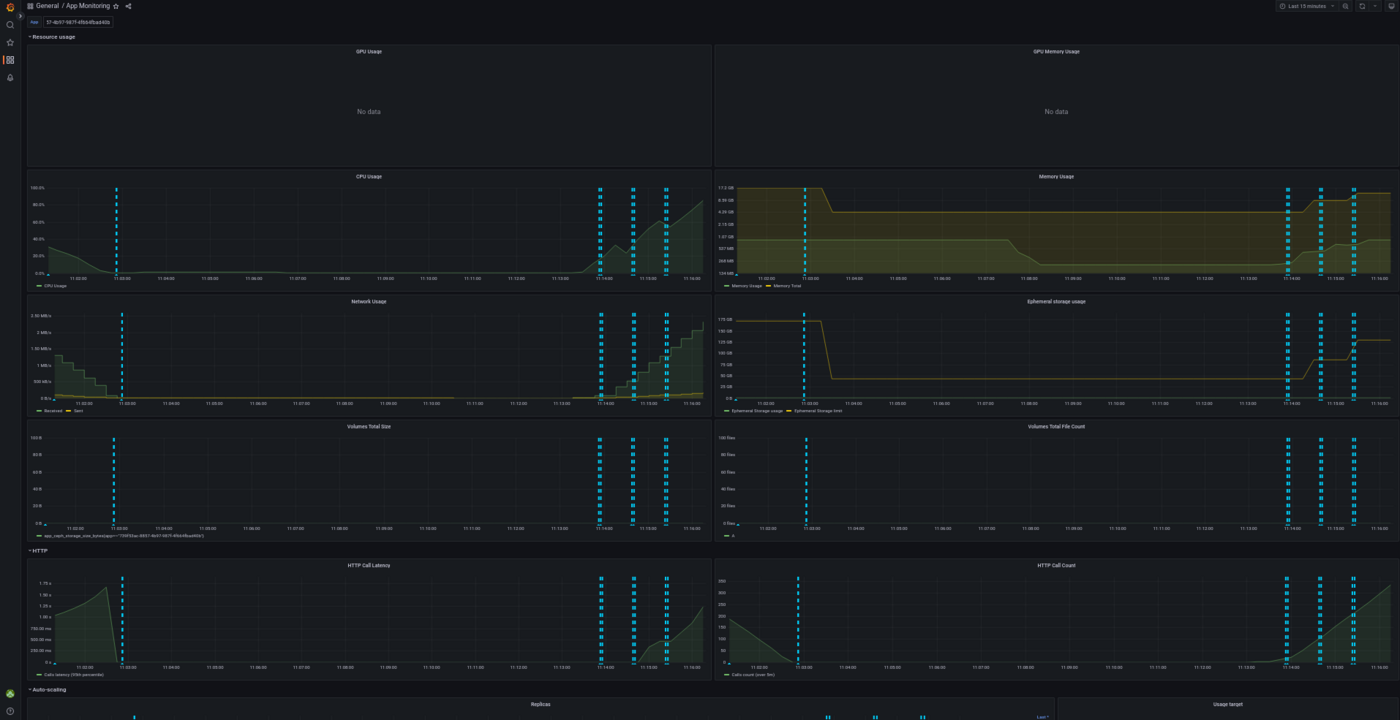
With this dashboard, you can see the percentage of CPU used in real time, the HTTP latency of your API, the autoscaling of the app, network bandwidth and more. Vertical blue bars show scaling events.
Here is the result for the CPU load, overall (all replicas combined):
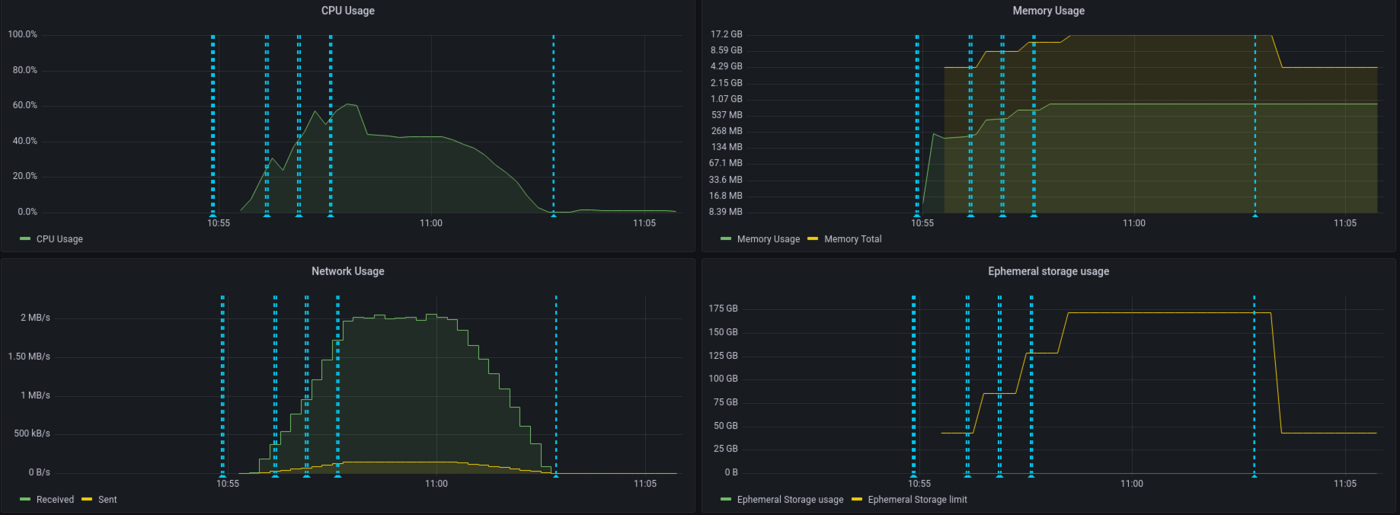
We can see that our app has scaled a few times and hasn't reach maximum capacity usage, thanks to autoscaling. Let's now take a look at the latency of our application:
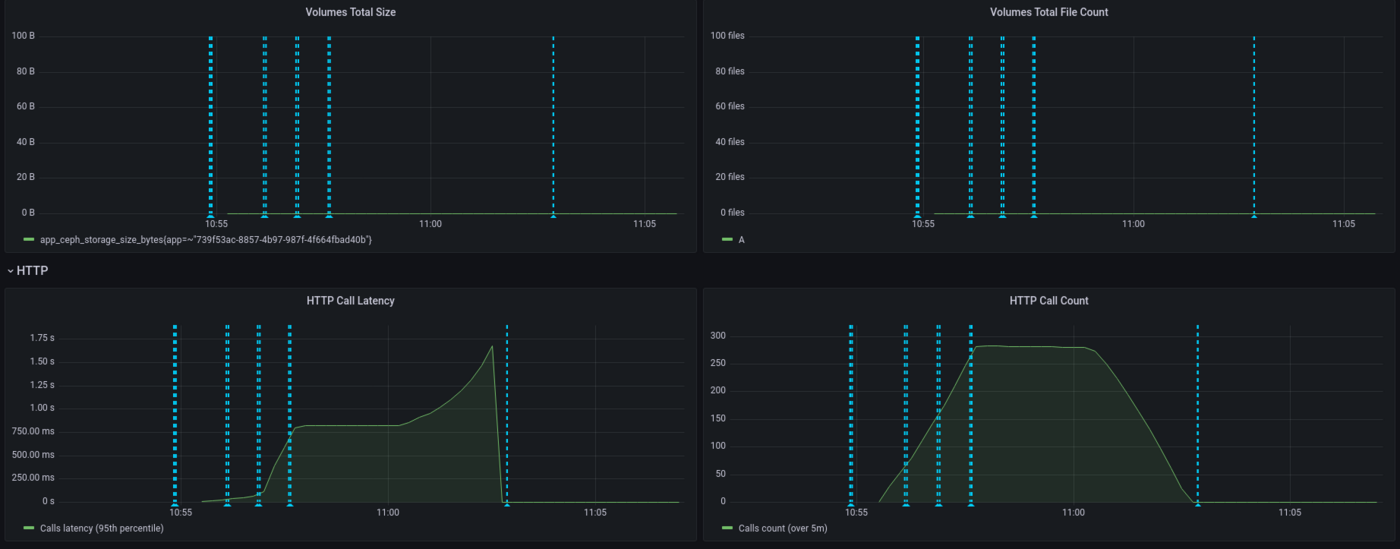
Here we see that the latency has increased gradually, since we have a spawn rate of two new users per second. API latency was stable with approximately 750ms then peaked to 1.5s.
Again, interpretation will depend on your needs. Do we need to provide more CPU because the latency is too high? This question will vary depending on your customers need. For an anti-spam, adding 1 second is quite big for a company receiving thousands of mails per day, not so disturbing if it's a dozen per day. Let's now take a look at the scaling of our application:
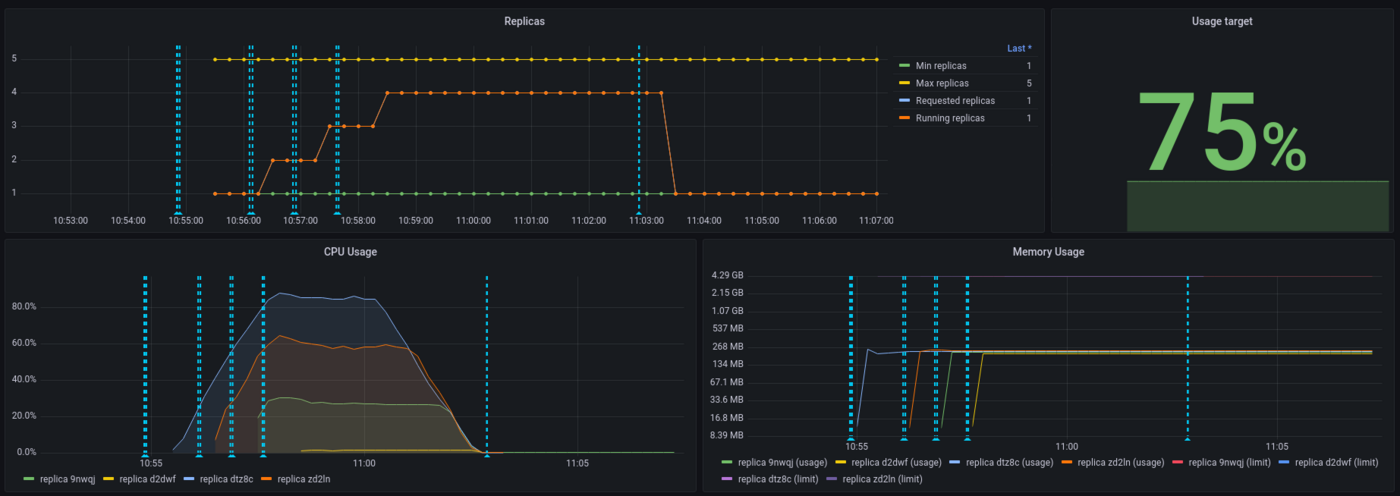
We can see that the threshold has been capped at 75% for the autoscaling and this has been respected. On the 5 replicas provided to the application, 4 have been used.
As a conclusion, both Locust and AI Deploy Monitoring are useful to interpret results but, more than tools, the most important thing is to define realistic workloads and performance criterias.
Last point : while Locust is measuring an end-to-end latency (from Locust virtual machine here, to the API model deployed), AI Deploy monitoring is only measuring backbone latency (from the query to the answer). That's why latency values are higher on Locust side, reaching 2.5 seconds.
Go further
Locust official documentation : Locust.io
Comparison of load testing tools : Comparison of load testing tools
If you need training or technical assistance to implement our solutions, contact your sales representative or click on this link to get a quote and ask our Professional Services experts for a custom analysis of your project.
Feedback
Please send us your questions, feedback and suggestions to improve the service:
- On the OVHcloud Discord server

