AI Endpoints - Build a RAG Chatbot with LangChain
584 Views
AI Endpoints is covered by the OVHcloud AI Endpoints Conditions and the OVHcloud Public Cloud Special Conditions.
Introduction
In this tutorial, we'll show you how to build a Retrieval Augmented Generation (RAG) chatbot that enhances answers by incorporating your own custom documents into the LLM’s context.
To do this, we will use LangChain, a powerful open-source framework that simplifies working with LLMs in both Python and JavaScript. Combined with OVHcloud AI Endpoints which offers both LLM and embedding models, it becomes easy to create advanced, production-ready assistants.
Definition
Retrieval Augmented Generation (RAG): Instead of relying solely on a model's built-in knowledge, RAG injects your data into the prompt to improve relevance.
Here’s how it works:
- Your documents are converted into vectors using an embedding model.
- When the user asks a question, it’s also turned into a vector.
- A similarity search is performed to find the most relevant data chunks.
- These are fed to the LLM as context, enabling grounded, accurate responses.
LangChain handles all these steps in one convenient pipeline.
Instructions
Set up the environment
In order to use AI Endpoints APIs easily, create a .env file to store environment variables:
Make sure to replace the token value (OVH_AI_ENDPOINTS_ACCESS_TOKEN) by yours. If you do not have one yet, follow the instructions in the AI Endpoints - Getting Started guide.
Then, create a requirements.txt file with the following libraries:
Then, launch the installation of these dependencies:
Importing necessary libraries and variables
Once this is done, you can create a Python file named chat-bot-streaming-rag.py, where you will first import Python librairies as follows:
After these lines, load and access the environnement variables of your .env file:
Then add the main Python code:
Prepare your knowledge base
Create a folder named rag-files and place your .txt, .md, or other text-based documents there. These will be converted into embeddings and used during retrieval.
You can find example files in our public-cloud-examples GitHub repository.
Run the RAG chatbot
Run the following command:
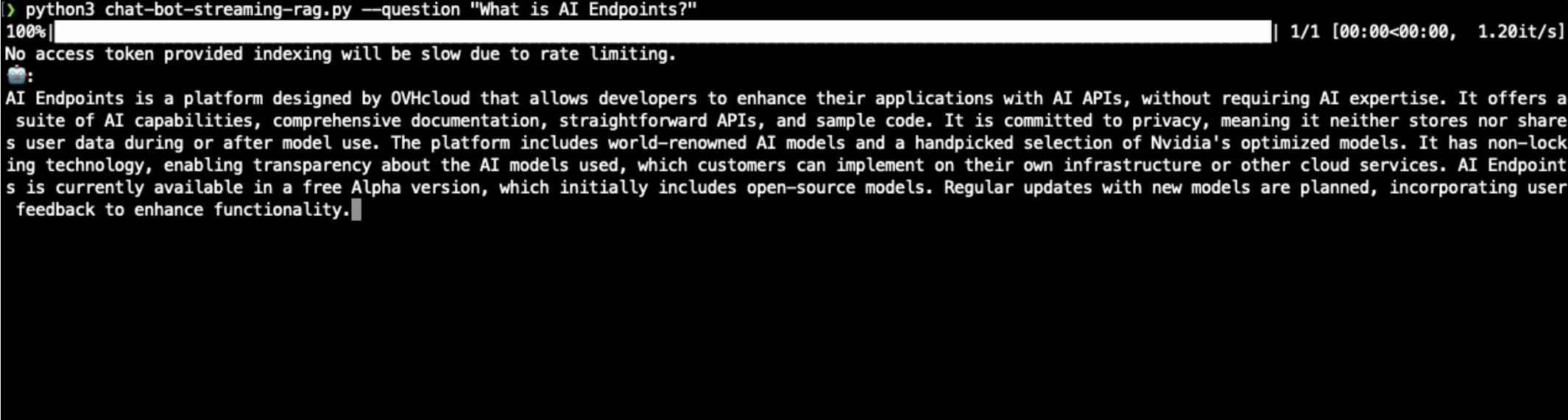
Compare this to a non-RAG chatbot, you’ll see much more specific, informed answers when documents are injected into the context.
Indeed, here is a comparison of not using RAG:

and using RAG:
Conclusion
You've now created a Retrieval-Augmented Generation (RAG) chatbot using your own documents and the OVHcloud AI Endpoints platform. LangChain’s integration with Chroma and embedding models makes RAG implementation straightforward—even production-ready.
Going further
If you want to go further and deploy your chatbot in the cloud, making your interface accessible to everyone, refer to the following articles and tutorials:
- AI Deploy – Tutorial – Build & use a custom Docker image
- AI Deploy – Tutorial – Deploy a Gradio app for sketch recognition
If you need training or technical assistance to implement our solutions, contact your sales representative or click on this link to get a quote and ask our Professional Services experts for a custom analysis of your project.
Feedback
Please feel free to send us your questions, feedback, and suggestions regarding AI Endpoints and its features:
- In the #ai-endpoints channel of the OVHcloud Discord server, where you can engage with the community and OVHcloud team members.

